

15 Data Structures that Power Distributed Databases

Distributed Databases are the backbone of modern large-scale applications, powering everything from real-time analytics to global e-commerce platforms.
Behind the scenes, these systems rely on specialized data structures to enable fast lookups, efficient storage, and high-throughput operations, even when managing terabytes of data.
In this article, we'll explore 15 key data structures that power modern distributed databases.
1. Hash Indexes
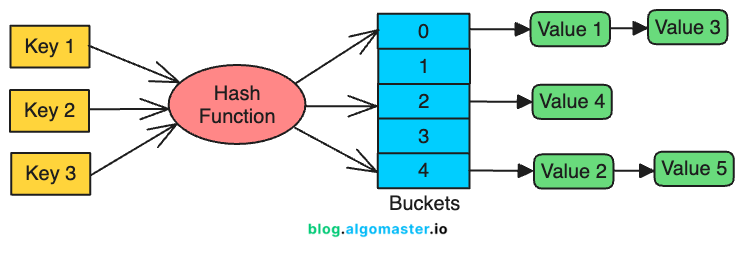
A hash index is a data structure that efficiently maps keys to values using a hash function.
The hash function converts a given key into an integer, which is used as an index in a hash table (buckets) to store and retrieve values.
This indexing technique is optimized for fast lookups and insertions, making it ideal for operations like:
Inserting or finding a record with
id = 123
In most cases, hash indexes provide an O(1) average-time complexity for insertions, deletions, and lookups.
Hash Indexes are commonly used in key-value stores (e.g., DynamoDB) and caching systems (e.g., Redis) where quick access to data is crucial.
2. Bloom Filters
A Bloom filter is a space-efficient, probabilistic data structure used to test set membership.
It answers the question: "Does this element exist in a set?"
Unlike traditional data structures, a Bloom filter does not store actual elements, making it extremely memory-efficient.
It starts as a bit array of size m, initialized with 0s, and relies on k independent hash functions, each of which maps an element to one of the m positions in the bit array.

How It Works
Insertion: When an element is added, it is passed through the k hash functions, each mapping it to an index in the bit array. The bits at these positions are set to 1.
Lookup: To check if an element is present, it is again passed through the same k functions.
If all corresponding bits are 1, the element is probably in the set (though false positives can occur).
If any bit is 0, the element is definitely not in the set.
Bloom filters allow databases to efficiently check whether a key might exist in a dataset, helping to avoid unnecessary disk lookups in places where the key is guaranteed to be absent. They are widely used in systems like SSTables in LSM trees (e.g., Apache Cassandra) and database partitions for fast key lookups.
3. LSM Trees (Log-Structured Merge Trees)
A Log-Structured Merge (LSM) Tree is a write-optimized data structure designed to handle high-throughput workloads efficiently.
Unlike B-Trees, which modify disk pages directly, LSM Trees buffer writes sequentially in memory and periodically flush them to disk, reducing random I/O operations.
This makes them ideal for write-heavy workloads.
How LSM Trees Work

Writes (Inserts, Updates, Deletes)
New writes are first stored in an in-memory structure called a MemTable (typically a Red-Black Tree or Skip List).
Once the MemTable reaches a certain size, it is flushed to disk as an immutable SSTable (Sorted String Table).
This sequential write pattern ensures fast insertions while avoiding costly disk seeks.
Reads
Reads first check the MemTable (fast in-memory lookups).
If not found, the search moves to recent SSTables.
A Bloom Filter is often used to quickly determine whether a key exists in an SSTable.
If found, the key is retrieved via binary search.
Compaction (Merging SSTables)
Over time, multiple SSTables accumulate, increasing read overhead.
To optimize storage and retrieval, the system merges smaller SSTables into larger ones.
Compaction removes duplicate, obsolete, or deleted records, reducing disk space.
LSM Trees are widely used in high-scale NoSQL databases like: Apache Cassandra, Google Bigtable and RocksDB.