

20 AI Concepts Explained in 20 Minutes

Learning AI can feel overwhelming. If you are not working directly in AI, it can feel like learning an entirely new language.
But like any technical topic, AI becomes much easier once you understand the fundamentals behind large language models (LLMs) and the modern tools built around them.
In this article, we will break down 20 of the most important AI concepts in the simplest way possible, with clear explanations and intuitive examples.
📣 Unblocked: The context layer your AI tools are missing (Sponsor)

Many developer tools promise context-aware AI, but having data access doesn’t automatically mean agents know when to use it.
Real context requires understanding. Unblocked synthesizes knowledge from your codebase, PRs, discussions, docs, project trackers, and runtime signals. It connects past decisions to current work, resolves conflicts between outdated docs and actual practice, respects data permissions, and surfaces what matters for the task at hand.
With Unblocked:
Coding agents like Cursor, Claude, and Copilot generate output that aligns with your actual architecture and conventions
Code review focuses on real bugs rather than stylistic nits
You find instant answers without interrupting teammates
See how Unblocked works.
Foundations
1. Neural Network
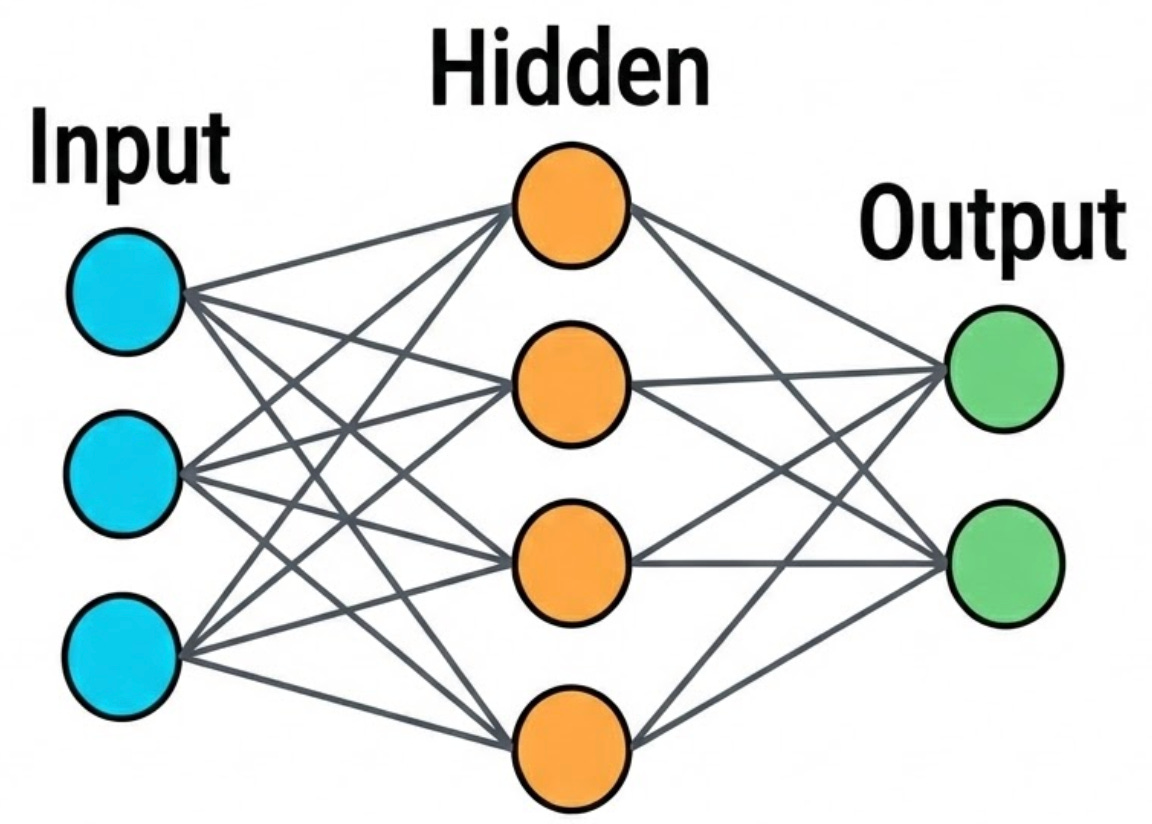
At its core, a neural network is a stack of connected layers made up of simple units called neurons. Data enters through the input layer, moves through one or more hidden layers where the model learns useful patterns, and then produces a final prediction at the output layer.
A helpful way to picture this is as a series of refinement steps. The same input gets transformed again and again, with each layer extracting slightly higher-level features than the one before it. In image models, early layers often pick up simple signals like edges and textures. Deeper layers combine those signals into shapes and parts, and later layers can represent full objects.
The connections between neurons have weights, numbers that control how strongly one neuron influences another. Training is essentially the process of adjusting these weights so the network’s outputs become more accurate.
Modern large language models contain an enormous number of such weights, often in the tens or even hundreds of billions.
2. Transfer Learning
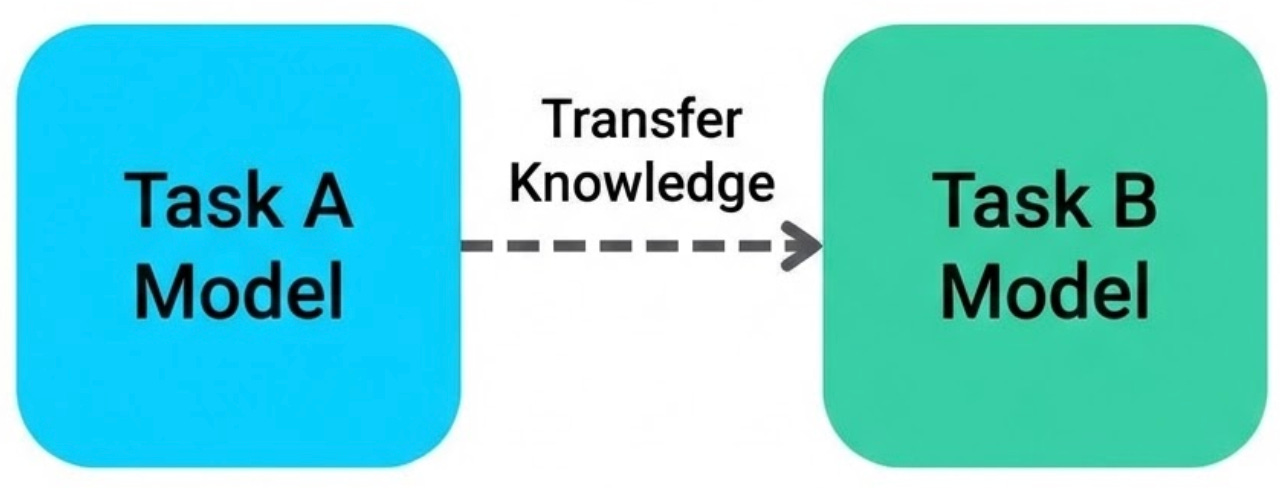
Training a neural network from scratch takes a huge amount of data and compute. Transfer learning changes the game. Instead of starting over, you take a model that has already been trained on a broad task and adapt it for a new, more specific one. Most of what the model learned still applies, so you get a strong head start.
A simple way to think about it is skill reuse. If you have already learned the basics, you can pick up a new variation much faster because the fundamentals do not need to be relearned. In the same way, a pretrained model already understands many general patterns in data, so fine-tuning it for your use case takes far less effort.
This is actually how most modern AI works. Someone trains a massive general-purpose model (the “foundation model”), and then you adapt it for your specific task.
The Transformer Stack
3. Tokenization
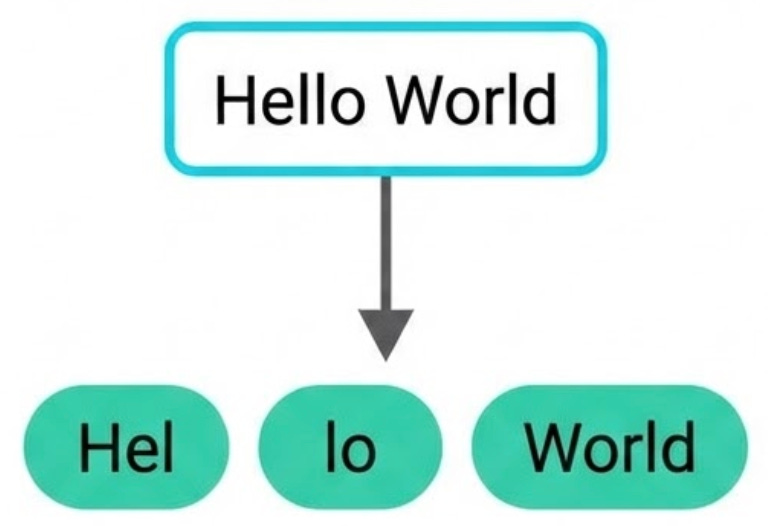
Before a model can work with text, it first has to convert that text into smaller units called tokens. A token can be a full word, a part of a word, a punctuation mark, or sometimes even a single character. This is the model’s “alphabet” for reading and writing language.
For example, the word “happiness” might be split into subword tokens like “hap”, “pi”, and “ness”, while a common word like “cat” might remain a single token. In general, common words tend to map cleanly to one token, while longer or rarer words get broken into smaller pieces.
Why not just use whole words?
Because the number of possible words is enormous, and it keeps growing. Proper nouns, slang, typos, domain-specific terms, and words from different languages would explode the vocabulary size.
Tokenization solves this by using a fixed vocabulary (often around 30,000 to 100,000 tokens) built from common words and reusable subword chunks. That way, even if the model has never seen a word before, it can still represent it by combining familiar pieces.
4. Embeddings
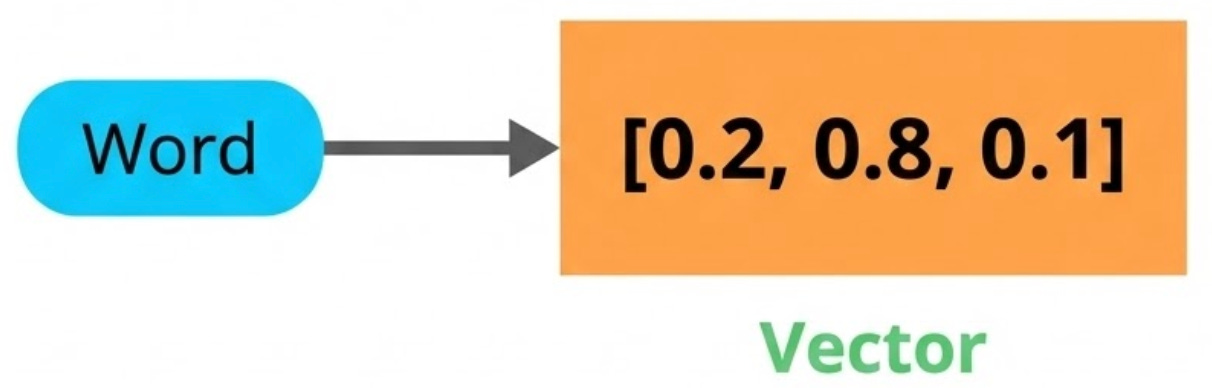
Once text is split into tokens, each token gets converted into an embedding, a vector (basically a list of numbers) that captures what the token means.
You can think of embeddings as coordinates in a high-dimensional map. Words with similar meanings end up close to each other, while unrelated words are far apart. For example, “king” and “queen” are located near each other in this space, whereas “king” and “refrigerator” are much farther apart.
These vectors usually have hundreds or even thousands of dimensions. While that sounds abstract, those dimensions capture meaningful patterns. The difference between “king” and “queen” is similar to the difference between “man” and “woman.”
The model does not understand language symbolically the way humans do. Instead, it learns meaning through geometry, by organizing words in a space where relationships become distances and directions.
5. Attention
Here’s the problem: the meaning of a word depends on context. “Bank” means something different in “river bank” versus “bank account”. Embeddings alone don’t solve this because they start as fixed vectors per token.
Attention is the mechanism that addresses this. It lets each token look at every other token in the input and decide which ones matter. When processing “bank” in “I sat by the river bank”, the attention mechanism focuses on “river” and adjusts the representation of “bank” accordingly.
This was the key innovation that unlocked modern AI. Before attention, models processed words one at a time, left to right. Attention lets the model see everything at once and figure out what’s relevant.
6. Transformer
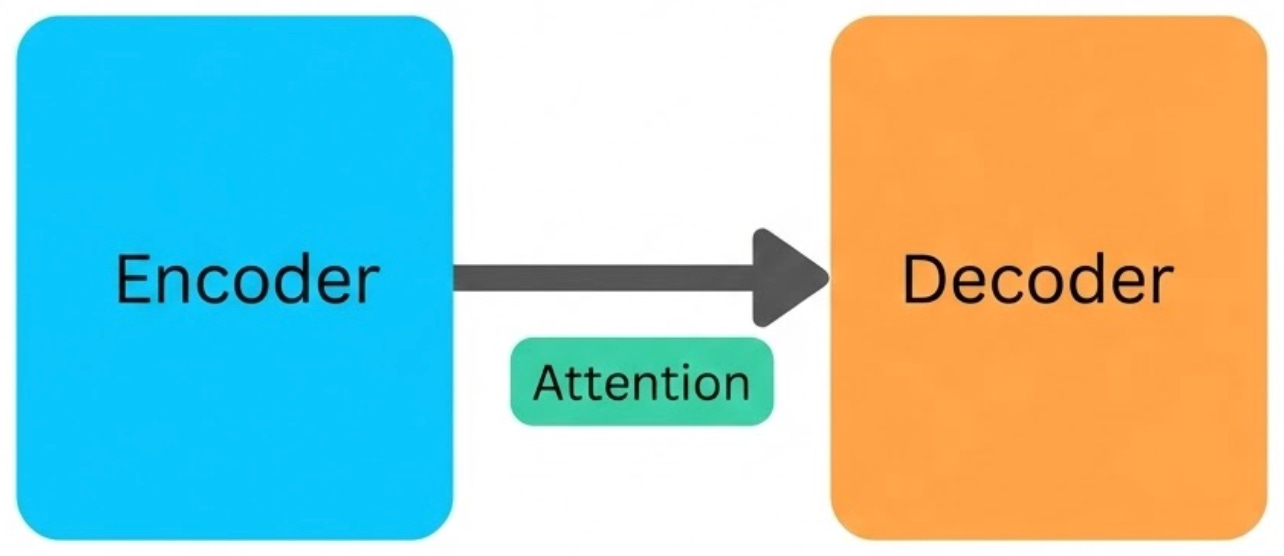
The transformer is the architecture that ties all of this together. It was introduced in a 2017 paper titled “Attention Is All You Need” and replaced the strictly sequential, word-by-word processing used in earlier models with attention as the central mechanism.
A transformer stacks multiple layers of attention and feed-forward networks. Each layer refines the representation of the input. Early layers tend to capture basic grammar. Middle layers pick up relationships between concepts. Later layers handle more complex reasoning.
One of the biggest advantages of transformers is that they process all tokens in parallel instead of one at a time. This makes training far more efficient on modern hardware like GPUs and enables models to scale to massive sizes. GPT, Claude, Gemini, Llama, and most other leading AI systems today are all built on transformer architectures.
In simple terms, text is converted into tokens, tokens become vectors, and stacked attention layers learn how those vectors relate and interact. That process forms the backbone of modern language models.
Large Language Models
7. LLM (Large Language Model)

A large language model (LLM) is essentially a transformer trained on an enormous amount of text, often hundreds of billions to trillions of tokens pulled from books, websites, code, and many other sources. The training objective sounds almost too simple: predict the next token.
That’s it. That’s the whole trick. But by doing this across trillions of examples, the model develops something that looks a lot like understanding, language, facts, reasoning patterns, even a degree of common sense. Most well-known systems today fall into this category, including GPT-style models, Claude, Gemini, and Llama.
The “large” part refers to the parameter count. Frontier models today have hundreds of billions of parameters, and training them costs tens of millions of dollars. But what you get is a model that can write code, answer questions, translate languages, and reason through problems it was never explicitly taught.
8. Context Window
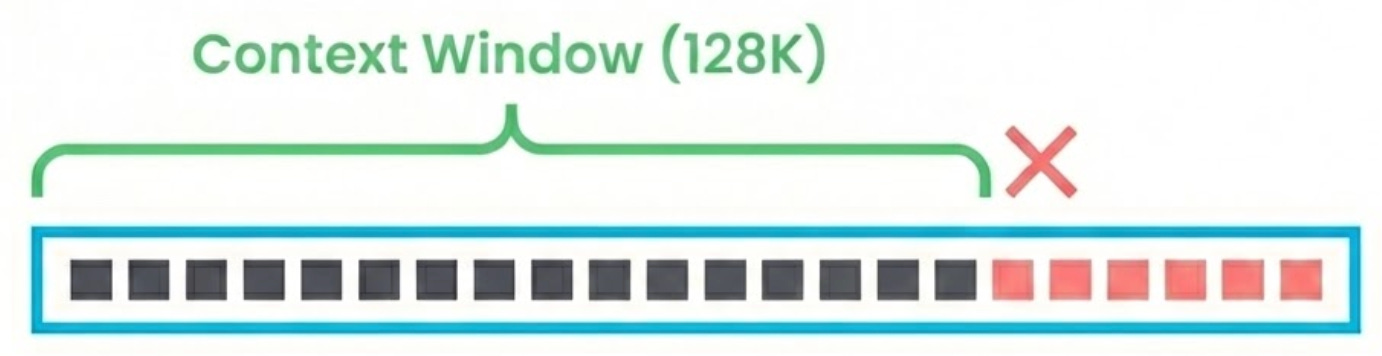
The context window is the maximum number of tokens a model can process at once, including both your input and the model’s generated output. You can think of it as the model’s working memory.
Early GPT models had a context window of 4,096 tokens (roughly 3,000 words). That felt limiting fast. Current models have pushed way beyond that. Claude supports 200K tokens. Gemini goes up to 1M. More context means the model can handle longer documents, longer conversations, and more information when forming a response.
However, there is a trade-off. Bigger context windows require significantly more memory and compute, which increases cost and latency. And even with large windows, models do not treat every part of the input equally.
Research has shown that performance often drops for information buried in the middle of very long inputs, a phenomenon commonly referred to as “lost in the middle.”
9. Temperature

When an LLM generates the next token, it doesn’t just pick one. It calculates a probability for every token in its vocabulary. Temperature controls how it chooses from those probabilities.
At temperature 0, it always picks the most probable token. The result is deterministic, focused, and predictable. At temperature 1, it samples proportionally to the probabilities, so you get more variety and surprise. Above 1, things get increasingly random, more creative maybe, but also less coherent.
In practice, a few simple rules work well:
Low temperature (0 to 0.3): best for precise tasks like code generation, structured extraction, summaries, and anything where correctness matters more than originality.
Medium temperature (0.5 to 0.8): good for brainstorming, alternative phrasings, marketing copy, and creative writing where variety is useful.
High temperature (1+): can be fun for playful ideation, but it often reduces coherence and can quickly produce nonsense, especially in longer outputs.
10. Hallucination
This is one of the most common issues people encounter with language models. A hallucination happens when an LLM produces something that sounds confident and believable, but is actually incorrect. It might reference a research paper that does not exist, invent a function in a software library, or present a fabricated statistic as if it were widely known.
Why does this happen?
Because LLMs are pattern completion engines at heart. They’re optimized to produce fluent, probable text, not to verify whether that text is true. If the most “natural” next sentence happens to be false, the model will produce it with the exact same confidence as a true one.
This makes hallucination one of the biggest practical challenges when using LLMs in real applications. Common ways to reduce it include retrieval-augmented generation (RAG), grounding responses in trusted source documents, and prompting the model to provide citations or acknowledge uncertainty.
Training and Optimization
At this point we have a powerful LLM, but it’s a generalist. How do you make it better at your specific task? And how do you shrink it enough to actually deploy?
These four techniques cover the spectrum from heavy customization to lightweight compression.
11. Fine-tuning
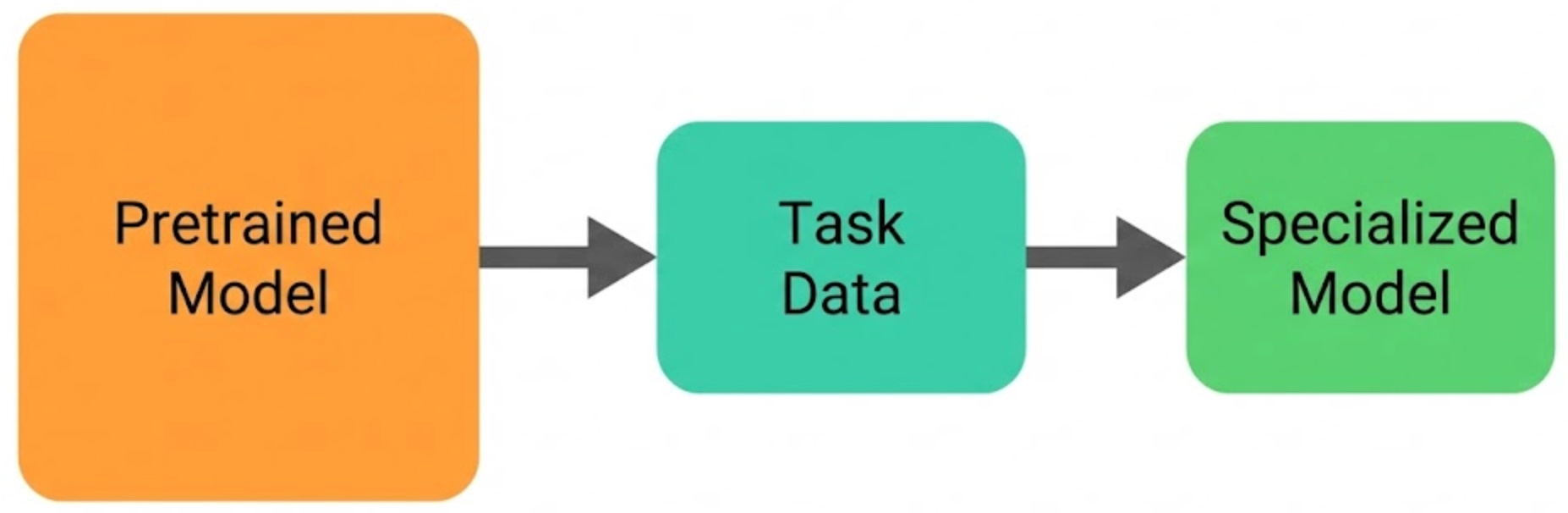
Fine-tuning starts with a pretrained model and continues training it on a smaller, task-specific dataset. The base model already understands general language patterns. Fine-tuning simply nudges it toward a particular domain, style, or behavior.
For example, if you want a model that performs well on medical question answering, you might fine-tune a general-purpose LLM on thousands of high-quality medical conversations or clinical explanations.
The trade-off is cost and infrastructure. Traditional fine-tuning updates most or all of the model’s parameters. That requires enough GPU memory to load the entire model along with optimizer states and gradients during training.
For a 70B parameter model, this typically means multiple high-end GPUs and significant compute resources. Fine-tuning can be powerful, but it is not lightweight.
12. RLHF (Reinforcement Learning from Human Feedback)
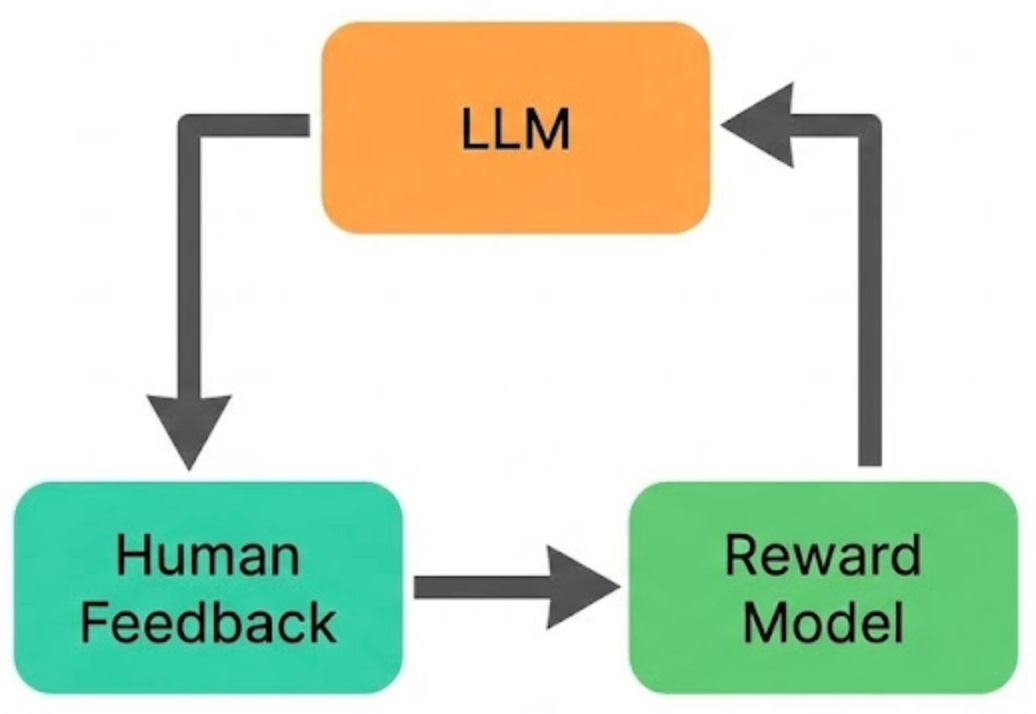
RLHF (Reinforcement Learning from Human Feedback) is one of the main techniques that turns “a model that predicts the next token” into “a model that feels helpful, polite, and safe to use.” It is a big reason modern chatbots feel like they are having a conversation, not just doing high-quality autocomplete.
At a high level, the process works like this:
Generate candidate answers. For a given prompt, the model produces multiple possible responses.
Humans rank them. Human reviewers compare those responses and rank them based on qualities like helpfulness, correctness, clarity, and safety.
Train a reward model. A separate model learns to predict which responses humans would prefer, based on those rankings.
Tune the LLM using that reward signal. The LLM is then optimized to produce answers that score higher according to the reward model.
This teaches the model behaviors that plain next-token prediction does not reliably produce: following instructions, refusing unsafe requests, being more balanced, and avoiding harmful or toxic directions.
Without RLHF (or other alignment methods), an LLM would be far more likely to continue text in whatever direction seems statistically plausible, even when that direction is unhelpful, misleading, or unsafe.
13. LoRA (Low-Rank Adaptation)
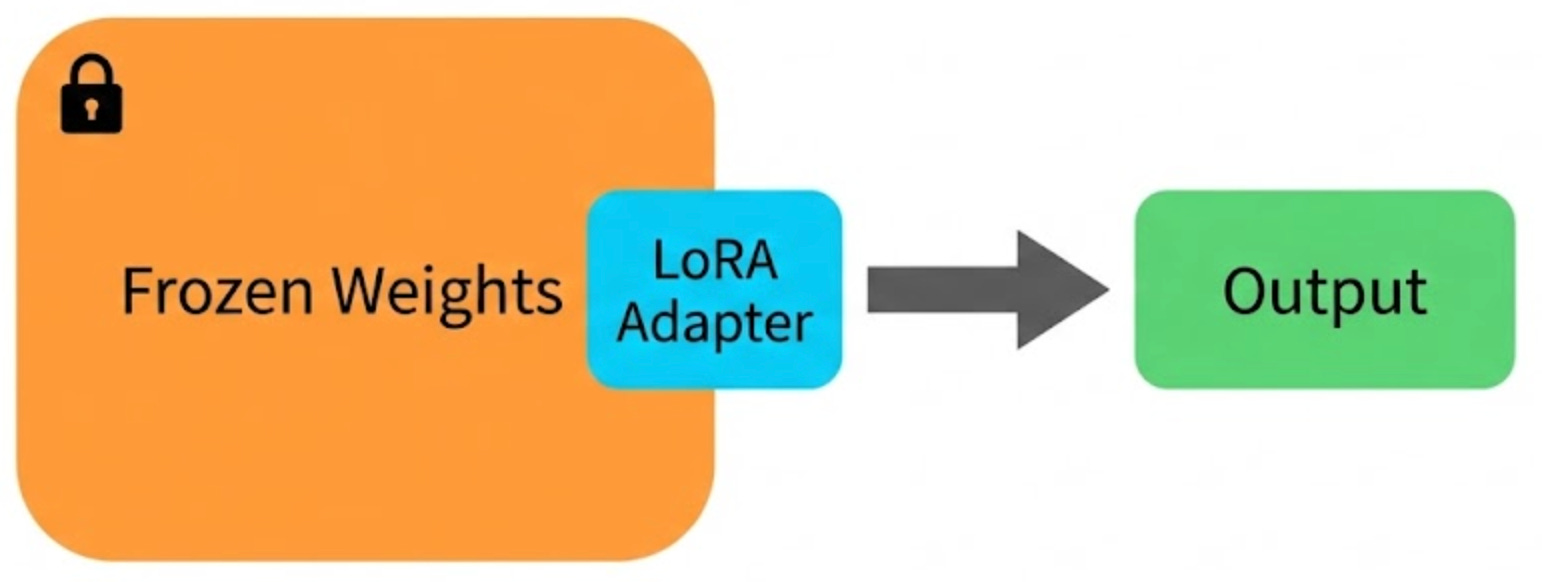
Fine-tuning every parameter in a large model, like a 70B parameter LLM, is extremely expensive. LoRA (Low-Rank Adaptation) takes a much more efficient approach.
Instead of updating the model’s original weights, it freezes them and adds small, trainable adapter matrices into selected layers. These adapters usually contain only about 0.1% to 1% of the total parameters.
The key insight is that the weight changes during fine-tuning tend to be “low-rank,” meaning they can be approximated by much smaller matrices without losing much quality. Instead of updating a 4096x4096 weight matrix, LoRA adds two small matrices (4096x8 and 8x4096) that together approximate the same change.
Why does this matter in practice?
You can fine-tune on a single GPU what would otherwise require a whole cluster. And you can swap different LoRA adapters in and out of the same base model, so you get multiple specialized versions without storing a full copy of the model for each one.
14. Quantization
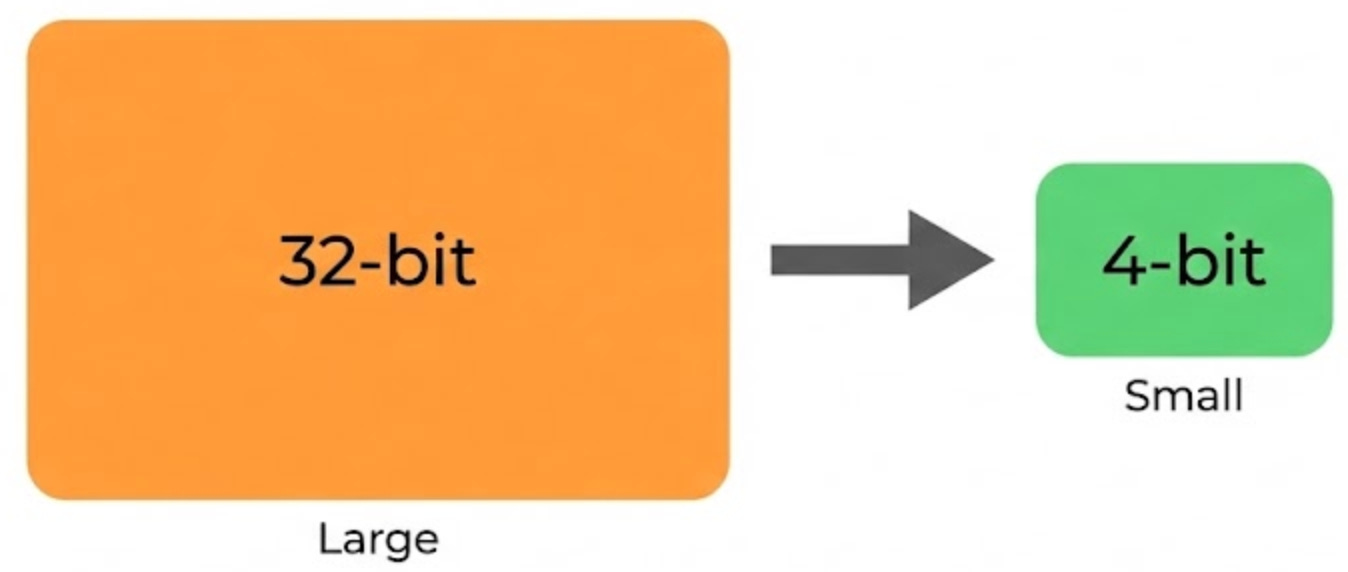
Quantization is a way to make models smaller and cheaper to run by storing their weights with fewer bits. In full precision, weights are often stored as 32-bit floating point values. Quantization reduces that to 16-bit, 8-bit, or even 4-bit, cutting memory usage dramatically.
The basic math is straightforward: if you go from 32-bit to 4-bit, each weight uses 8× less memory, so the whole model becomes roughly 8× smaller.
For example, a 70B-parameter model can require well over 100GB of memory at full precision, but a 4-bit quantized version can fit into a few dozen GB. The quality drop is often smaller than you would expect, especially with 8-bit quantization, which tends to preserve performance well for many tasks.
This is one of the main reasons large models can run on consumer hardware. When you see someone running a 70B model on a desktop GPU or even a laptop, it is almost always a quantized checkpoint rather than the full-precision model.
Prompting and Reasoning
You’ve got a trained, optimized model. Now the question is: how do you actually get good output from it?
Turns out, a lot of it comes down to how you ask.
15. Prompt Engineering
Prompt engineering is the art of crafting your input to get better output. The same underlying question, phrased differently, can lead to dramatically different responses.
For example, a vague prompt like “explain databases” usually results in a high-level overview. But something more specific like “explain how B-tree indexes work in PostgreSQL, with a concrete example using a users table” gives the model clear direction.
Here are few techniques that consistently improve results:
Role context: “You are a senior database engineer.”
Few-shot examples: Provide sample inputs and outputs to show the format and depth you expect.
Step-by-step decomposition: Break complex tasks into smaller, explicit steps.
Constraints: Limit length, specify structure, or define the desired tone.
Prompt engineering is not a workaround. It is the primary interface for interacting with LLMs. The difference between a vague prompt and a carefully constructed one can mean the difference between shallow, generic output and something that is accurate, structured, and production-ready.
16. Chain of Thought (CoT)

Chain of thought is a prompting technique where you ask the model to show its reasoning step by step before giving a final answer. Simple idea, but it makes a surprisingly big difference on math, logic, and multi-step reasoning.
Here’s a concrete example.
Direct prompt: “What is 47 x 23?”
The model might output 1,071 (wrong) because it’s pattern-matching rather than actually computing.
Chain of thought prompt: “What is 47 x 23? Think step by step.”
The model walks through: 47 x 20 = 940, 47 x 3 = 141, 940 + 141 = 1,081 (correct).
By making the model generate intermediate steps, you’re giving it “scratch space” to work through the problem instead of jumping straight to an answer. Research shows this can improve accuracy on reasoning benchmarks by 20-40%.
Better answers come from letting the model think out loud, rather than forcing it to jump straight to a conclusion.
Building AI Systems
Knowing individual concepts is useful, but real AI products are systems, not solo models. This last section covers the building blocks engineers use to put it all together.
17. RAG (Retrieval-Augmented Generation)
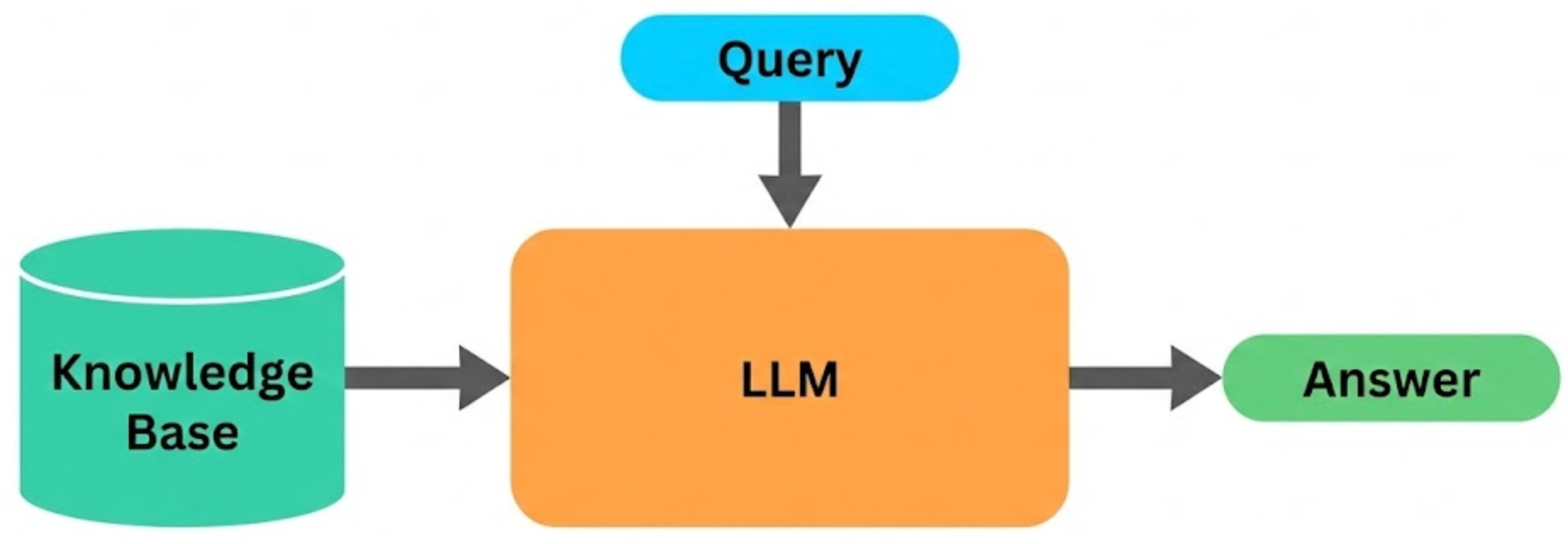
Remember the hallucination problem? RAG (Retrieval-Augmented Generation) is one of the most effective ways to reduce it.
The idea is simple. Before the model generates a response, the system first retrieves relevant documents from a knowledge base and inserts them into the prompt as context. The model then answers using that information, instead of relying only on what it learned during training.
For example, imagine a customer support bot. When a user asks about your refund policy, the system first fetches the actual policy document, then the model generates an answer based on what it reads. The response is grounded in real, up-to-date information rather than vague recollection.
What makes RAG especially powerful is that it separates knowledge from reasoning.
The LLM handles understanding and explanation.
Your document store provides the facts.
If the information changes, you do not need to retrain the model. You simply update the documents it retrieves. This makes RAG practical, scalable, and far more reliable for real-world applications where accuracy matters.
18. Vector Database
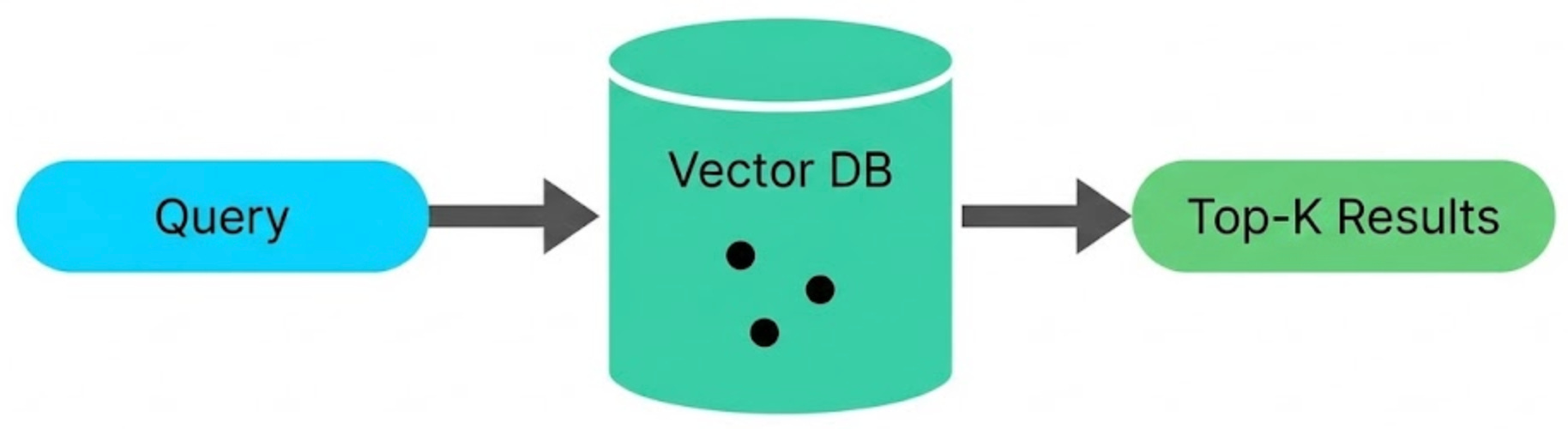
So how does RAG actually find the right documents? That is where vector databases come in. They store embeddings, the numerical vectors we discussed earlier, and allow you to search by meaning rather than exact keywords.
Here is how the flow works. Your documents are first split into smaller chunks. Each chunk is converted into an embedding, and those embeddings are stored in a vector database.
When a user asks a question, the query is also converted into an embedding. The database then searches for the stored vectors that are closest to the query vector and returns the most relevant chunks.
This creates a fundamentally different kind of search. A keyword search for “how to cancel my subscription” might miss a document titled “account termination process.” A vector search can still find it because the underlying meaning is similar, even though the wording is different.
Some widely used vector databases include Pinecone, Weaviate, Qdrant, and Chroma. PostgreSQL can also support vector search through the pgvector extension, which makes it possible to add semantic search capabilities to a familiar relational database.
19. AI Agents
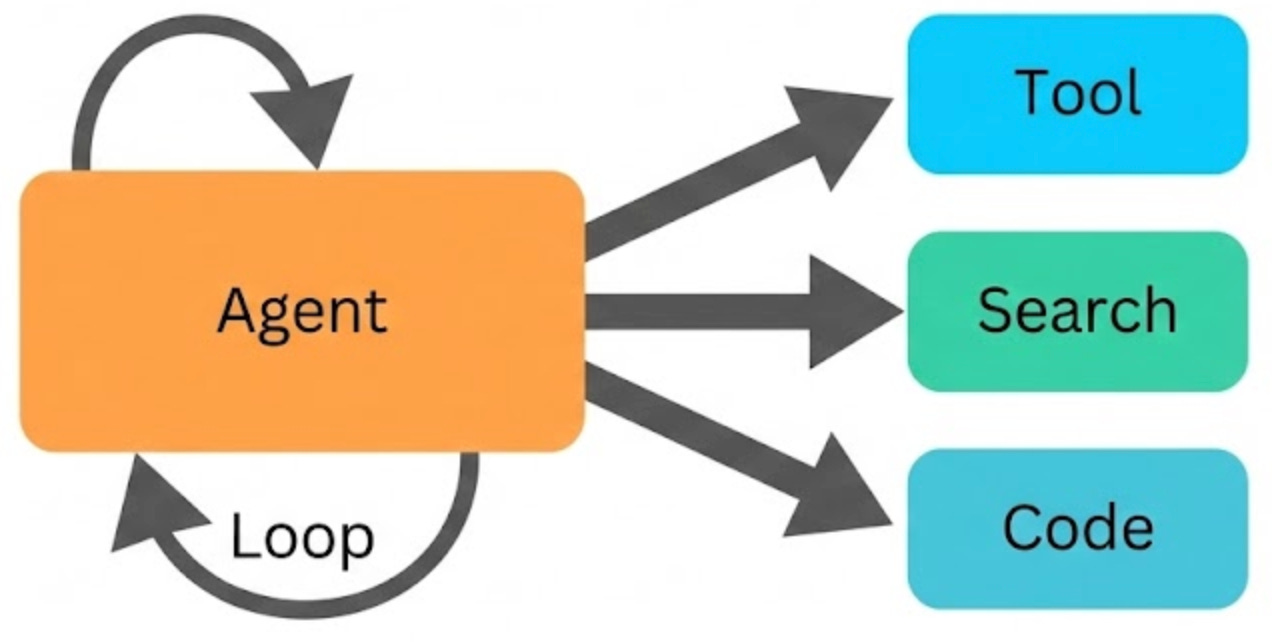
An AI agent is an LLM that does more than generate text. It can take actions, make decisions, and interact with external tools to complete tasks. While a chatbot mainly responds with language, an agent can browse the web, run code, query databases, call APIs, and chain these actions together to achieve a goal.
Most agents follow a simple control loop:
Observe the current state or new information.
Think about what to do next.
Act by using a tool or taking a step.
Repeat until the task is complete.
The LLM serves as the decision-making engine that drives this loop.
For example, a coding agent might read a bug report, search the codebase for relevant files, analyze the logic, write a fix, run tests, see failures, revise the fix, and run the tests again until everything passes. Each step involves the model deciding what action to take next based on the latest results.
The biggest challenge is reliability. Every step has some chance of failure, and those risks multiply across long action chains. If a 10-step task has 95% accuracy per step, the chance of everything working perfectly end-to-end drops to about 60%.
That is why modern agent frameworks invest heavily in planning, validation, retries, and self-correction to keep multi-step workflows on track.
20. Diffusion Models
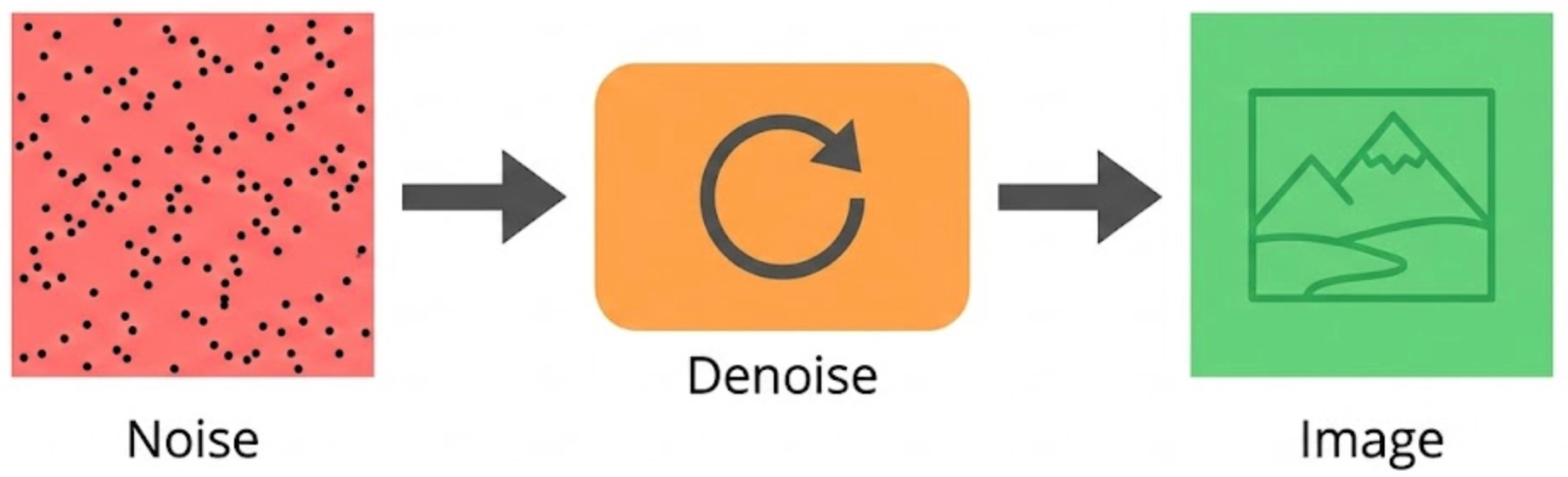
Diffusion models are the engine behind many modern image generators, including DALL·E, Midjourney, and Nano Banana (Gemini). The core idea is a bit counterintuitive: they learn to generate images by first learning how to corrupt them.
During training, you start with real images and gradually add random noise until the image becomes almost pure static. The model is then trained to reverse that process, step by step, learning how to remove a little noise at a time and reconstruct the original image.
At generation time, you flip the pipeline. You begin with pure noise, and the model iteratively denoises it into a coherent image, guided by your text prompt. Each step makes the image slightly more structured, typically over something like 20–50 denoising steps.
The term “diffusion” comes from physics, where randomness spreads through a medium like ink dispersing in water. In diffusion models, noise spreads through the image in a similar way, and the model learns the reverse trajectory: how to go from randomness back to signal.
This same idea now extends beyond images. Diffusion-style approaches are used for video generation, audio, 3D assets, and even scientific domains like molecule and protein structure generation.
Thank you for reading!
If you found it valuable, hit a like ❤️ and consider subscribing for more such content every week.
If you have any questions/suggestions, feel free to leave a comment.
Thanks for sharing 👏👏
Well explained in simple words