

10 Data Structures That Make Databases Fast and Scalable
From B-Trees to Bloom Filters

Have you ever wondered why modern databases are so fast and efficient, even when managing terabytes of data?
The answer lies in their underlying data structures and indexing techniques that enable efficient storage, retrieval, and management of data.
In this article, we'll look at 10 important data structures that make modern databases fast, reliable, and scalable.
1. Hash Indexes
A hash index is a data structure that maps keys to values using a hash function.
The hash function converts a key into an integer, which is used as an index in a hash table (buckets) to locate the corresponding value.
It is designed for fast insertion and lookup, such as:
Insert/Find a new record with
id = 123.
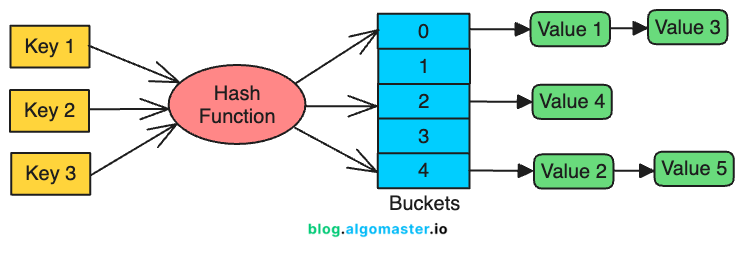
This structure provides O(1) average-time complexity for insertions, deletions, and lookups.
Hash indexes are widely used in key-value stores (eg., DynamoDB), and caching systems (eg., Redis).
2. B-Trees
A B-tree is a self-balancing tree data structure designed to store sorted data in a way that optimizes reads, writes, and queries on large datasets.
It minimizes disk I/O by storing multiple keys in a single node and automatically balances itself during insertions and deletions.

Unlike binary search trees, where each node has at most two children, B-Trees allow multiple children per node. The number of children is defined by the order of the B-Tree.
Internal nodes contain keys and pointers to child nodes and leaf nodes contain keys and pointers to the actual data.
Keys in each node are stored in sorted order, enabling fast binary searches.
B-Trees are widely used for indexing in relational databases (eg., MySQL).
While many NoSQL databases favor LSM Trees for write-heavy workloads, some use B-Trees for read-heavy scenarios or as part of their indexing strategy.