

Designing a Scalable “Likes” Counting System for Social Media

At first glance, counting “likes” on a social media post seems simple, just increment a number, right?
But at scale, this becomes a surprisingly complex distributed systems problem.

Imagine millions of users liking posts simultaneously, especially during viral moments. The system must remain fast, accurate, and resilient, even under heavy load.
Key Challenges include:
How do we handle hot posts that receive massive, sudden traffic?
How do we maintain consistency in likes count across distributed nodes?
How do we ensure performance and availability as the number of like events scales into the millions?
How do we make sure each user’s like is counted exactly once?
In this article, we’ll walk through how to design a scalable like-counting system starting from a basic design and gradually evolving it into a robust, distributed architecture.
Along the way, we’ll explore important system design concepts and trade-offs, including:
Caching
Sharding
Strong vs. Eventual Consistency
Asynchronous Processing
Message Queues
Deduplication (Idempotency)
We’ll also discuss how to support unlikes, and how to build features like trending posts using the like stream for real-time analytics.
Requirements
Before we jump into the design, let’s define what our “likes” system needs to support, both functionally and non-functionally.
1. Functional Requirements
Users can like and unlike a post by toggling the like button.
A user can like a post only once. If they press “like” again, it should be treated as an unlike.
Both the post owner and viewers should be able to see the total like count for a post.
The like count should update reasonably quickly after a like/unlike action.
Show a full list of all users who liked a post.
2. Non-Functional Requirements
High Throughput: The system should handle thousands of likes per second, including spikes from viral content (say a celebrity’s post).
Scalability: The system must be horizontally scalable (able to add servers/nodes to handle growth)
Highly Available: A failure in one component should not bring down the whole “likes” functionality.
Low Latency: Liking a post should feel instant. The displayed count can lag slightly but should stay reasonably up to date.
Consistency: We aim for eventual consistency — brief discrepancies in counts are acceptable, but they must reconcile quickly. Strong consistency is nice-to-have, not a must.
Durability: No likes should be lost, even during failures. Every like must be recorded persistently.
Idempotency: A user’s like should count only once, even if the action is retried or duplicated.
Analytics-Friendly: The system should support analytics use cases like identifying trending posts (e.g., most-liked posts in the last hour).
With these in mind, let’s begin with a simple solution and then evolve it into a scalable architecture by addressing each limitation.
Step-by-Step Design
1. Basic Single-Database Design
Let’s start with the most straightforward solution — storing likes in a single relational database.
We create a Likes table with columns like:
post_iduser_idtimestamp(optional)
id(auto-incremented)
Every time a user likes a post, we insert a new row into this table.
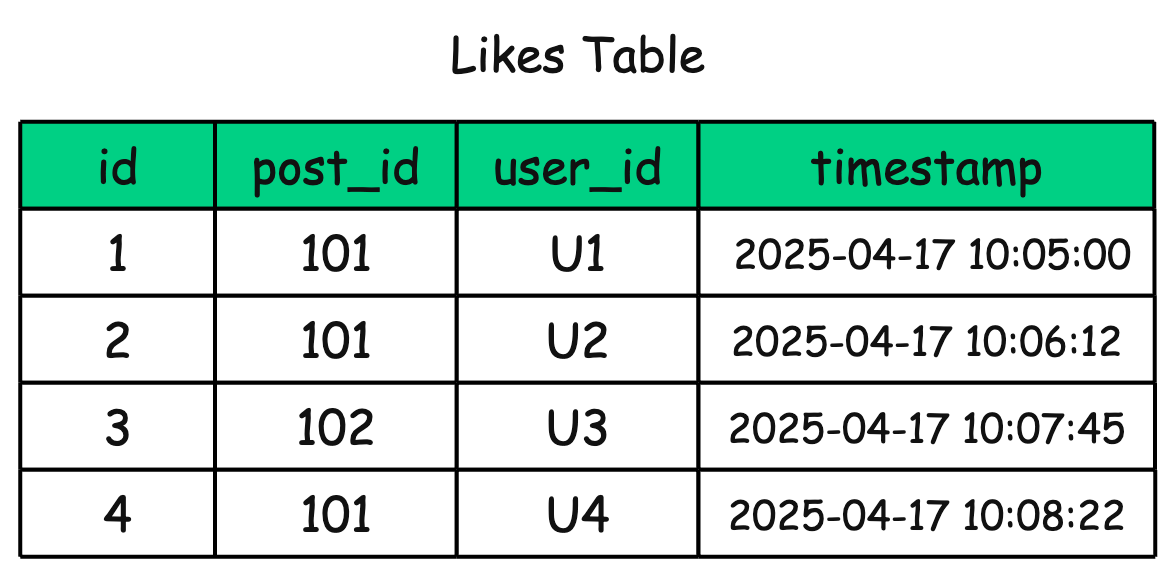
To get the total likes for a post, we simply run:
SELECT COUNT(1) FROM Likes WHERE post_id = X;Alternatively, we could maintain a like_count field in a Posts table and increment it on every like.
But for simplicity, let’s stick to querying the Likes table directly.
On unlike, we can simply delete the corresponding row from the Likes table.
DELETE FROM Likes WHERE post_id = 123 AND user_id = 'user_456';This approach also allows us to easily retrieve the list of users who liked a specific post using a simple query:
SELECT user_id FROM Likes WHERE post_id = X;To optimize read queries, we can add an index on
post_id, which improves lookup performance as the table grows.
Architecture
This setup is a typical monolith or simple web stack:

Likes Service: Handles "like" requests from users.
Likes Table (SQL): Stores each like action in the
Likestable
When a user likes a post, the likes service inserts a record into the database. When someone views a post, it queries the total likes from the same database.
Benefits
Simplicity and Strong Consistency: Once the DB insert is successful, any subsequent reads will reflect the updated count. Everyone, the liker and other users sees the updated value immediately.
Enforces Uniqueness Easily: We can add a
UNIQUE(post_id, user_id)constraint to ensure that each user can only like a post once. If a user tries to like the same post again, the DB will reject it.Easy to Query: Checking whether a user liked a post is a fast lookup on
(post_id, user_id).SELECT 1 FROM Likes WHERE post_id = X AND user_id = Y;
Drawbacks
Doesn’t Scale: Every like triggers a write. With millions of users, the DB quickly becomes a bottleneck. A single SQL database can’t handle that level of write throughput.
Expensive Count Queries: Using
COUNT(1)on large tables is slow. As posts gain millions of likes, counting them becomes a performance problem — even with indexing.High Latency: Each like inserts a row. Each post view might run a
COUNT(1)query. Under load, these operations can slow down the system significantly.Single Point of Failure: If the database goes down, users can’t like posts or see updated counts.
Limited Horizontal Scaling: You can add read replicas to spread reads, but writes still go to the primary database. Scaling vertically (more CPU/RAM) only goes so far.
This design is simple and correct, offering strong consistency and easy constraints.
But it falls apart at scale.
To handle real-world traffic with millions of users and viral posts, we need to evolve this architecture to improve performance, scalability, and availability.
2. Improving Read Efficiency – Caching and Aggregated Counts
In our basic design, reading the like count with COUNT(1) is expensive and hits the database hard — especially for popular posts.
To fix this, we introduce two improvements:
Maintain precomputed like counts
Use caching for fast reads
Precomputed Like Counts
Instead of computing the count on every read, we store it alongside the post. This can be done by:
Adding a
like_countcolumn in thePoststable, orCreating a separate
PostLikesCounttable with schema:(post_id, like_count)

Each time a user likes or unlikes a post, we increment or decrement this count. This turns a costly COUNT(1) query into a fast primary-key lookup.
Introduce a Cache Layer
We add an in-memory cache (e.g., Redis or Memcached) to store frequently accessed like counts:
The app checks the cache first.
If the data isn’t in the cache (cache miss), it queries the DB, then stores the result in cache.
Subsequent reads for the same post hit the cache, not the DB.
Updated Architecture

Cache Store (a distributed in-memory cache cluster): Stores
<post_id, like_count>pairs in memory for fast access.Posts Table: Stores aggregated like counts in either the
Poststable or a dedicated table.
Workflow
On a Like:
Insert a row into the
Likestable.Increment the
like_countin thePostsorPostLikesCounttable.UPDATE Posts SET like_count = like_count + 1 WHERE post_id = XIf both the like insertion and count update are in the same DB, we can wrap them in a single transaction for strong consistency.
BEGIN; -- 1. Insert into Likes table INSERT INTO Likes (post_id, user_id, timestamp) VALUES (123, 'user_456', NOW()); -- 2. Increment like count UPDATE Posts SET like_count = like_count + 1 WHERE post_id = 123; COMMIT;Invalidate or update the cache entry for that post’s count.
Note: We still need the
Likestable to log all the like events and find users who liked a post.
On Reading Like Count:
Check the cache.
On cache miss, query for
like_countfromPoststable, then populate the cache.SELECT like_count FROM WHERE post_id = X
Benefits
Fast Reads: Fetching the like count is now O(1) — either from cache or via a quick primary-key lookup. No more expensive aggregations over many rows.
Reduced DB Load: Cache absorbs most read traffic, especially for viral posts that are viewed repeatedly.
Strong Consistency (for a single server): A transactional write ensures that the
Likesrow and thelike_countupdate stay in sync.Simple Cache Model: We’re caching a single number (the count), which is easy to update or invalidate on write.
Drawbacks
Cache Inconsistency: When the like count changes in the DB, the cache needs to be updated or invalidated. Otherwise, clients may be shown stale data. A common pattern is:
1. Update DB 2. Invalidate cacheWrite Contention on Hot Posts: Now every like involves two writes (insert in the
Likestable + update in thePoststable). For popular posts, thelike_countrow can become a hotspot, causing lock contention in the DB. (We will address this later with sharding and other techniques.)Still Single Database: All likes still go through the same DB instance. While reads are faster, we haven’t solved write scalability yet.
Eventual Consistency in Caches: If using read replicas or multiple cache layers, some clients may see slightly stale counts due to replication lag or delayed cache updates. Usually acceptable within a short window (milliseconds to seconds).
Cache Memory Overhead: Storing every post’s count in cache uses memory. Fortunately, the data size is small, and infrequently accessed entries (e.g. old posts) can be evicted.
Despite the drawbacks, this step significantly improves read performance. Instead of recalculating likes for every view, we cache or store the count and serve it instantly.
But the write path is still centralized, and hot posts can create contention. To scale further, we need to distribute the write workload — which we’ll explore next.