

How LLMs are Actually Trained


In the last lesson, we learned how the Transformer architecture powers an LLM. In this one, we will discuss how LLMs are trained from scratch to become helpful assistants.
LLM training occurs in stages, with each step guiding the model to become more useful than the previous one. These stages are as follows:
Pretraining
Mid-training
Post-training
In general, each subsequent stage of training requires:
Less training data
Cleaner and more domain-specific datasets
More sophisticated algorithms
Let’s learn about each stage in more depth in the subsequent sections.
Pretraining
Pretraining is the first stage in LLM training that teaches it the basics of language (grammar, syntax, and semantic structure) and gives it foundational knowledge of the world.
Large datasets containing trillions of tokens of information scraped from the web are used for LLM pretraining. Some of these datasets are:
Common Crawl: A massive raw dataset obtained by scraping the web. Most other pretraining datasets are filtered down from it.
RefinedWeb: A cleaned dataset derived from Common Crawl, used to train Falcon models
C4 (Colossal Clean Crawled Corpus): A cleaned dataset derived from Common Crawl, introduced with Google’s T5 model
FineWeb: A cleaned dataset derived from Common Crawl with 15-trillion tokens, released by Hugging Face
The Pile: A dataset consisting of 22 smaller, high-quality datasets combined together, released by EleutherAI
Dolma: Dataset of more than 3 trillion tokens from AllenAI, used to train their Olmo models
An LLM is trained using the next-token prediction objective by minimizing the cross-entropy loss between the ground truth and predicted tokens at this stage. This is the most compute-intensive stage of the whole LLM training pipeline.
The resulting pretrained model is called the “Base model”, and it can generate subsequent tokens for a given prompt (not necessarily helpful ones).
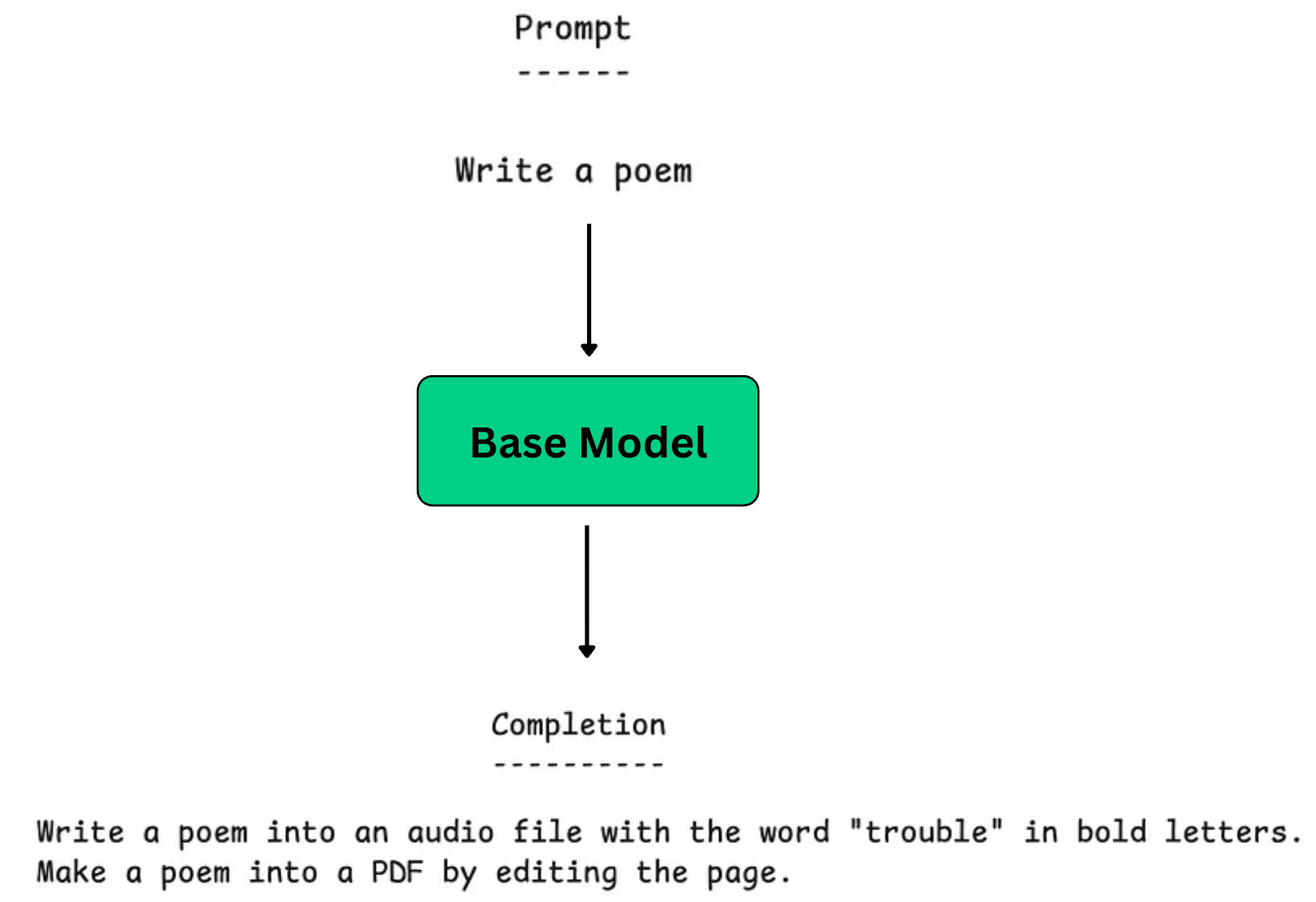
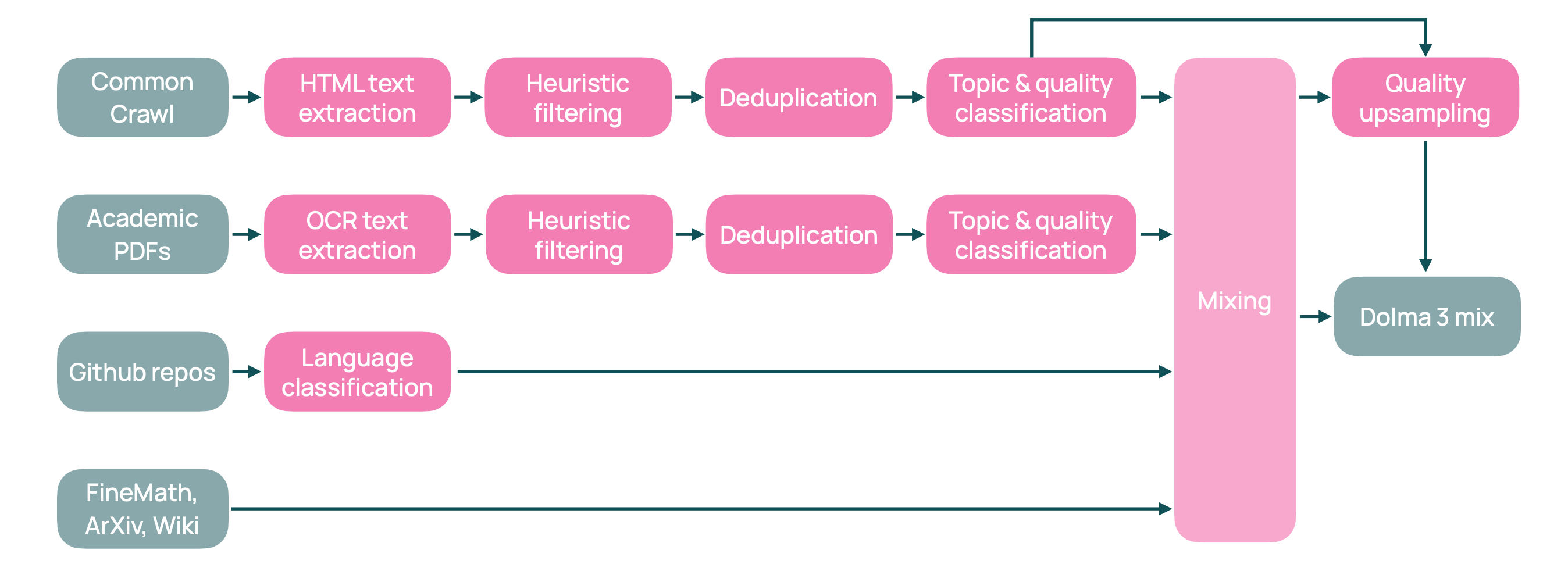
At this point, it would be very helpful to learn how a pretraining dataset is created from larger unfiltered datasets such as Common Crawl. Let’s look into how Dolma 3 Mix, the pretraining dataset used to train the Olmo 3 family of models, was created. This dataset contains approximately 6 trillion tokens!
Starting from raw web archives of Common Crawl, clean text is first extracted from them, and a technique called ‘Heuristic filtering’ is then applied, which involves:
Using URL filtering to remove spam and adult content
Applying length filters to remove documents that are either too short or too long
Filtering and removing documents that contain lots of symbols or insufficient quantities of alphabetic characters
Filtering and removing documents with a large amount of repetitive content inside them
Filtering and removing documents that contain Personally Identifiable Information (PII)
Filtering and removing documents that are in a language other than English
Applying sentence-level filters to find low-quality samples
The resulting documents then go through a stage of Deduplication. This is when documents are compared and copies that appear multiple times in the dataset are removed.
The deduplicated dataset is then further classified by topic and text quality and combined with other cleaned datasets from ArXiv, Wikipedia, GitHub repositories, and more.
The right mix of datasets is not guessed. Instead, small proxy models are trained on different dataset combinations, and evaluations determine which combination results in the best pretraining performance. The best-performing data is duplicated, while the lower-performing data is discarded. This step is called Quality-aware upsampling.
The resulting data mix is then used in the full pretraining.
Mid-training
Mid-training is the stage in which an LLM is trained on high-quality, domain-specific data to improve its capabilities. This data focuses on:
Very high-quality web text
Domains like health, law, math, code, and general knowledge
Improving reasoning (training with reasoning traces)
Improving instruction following (training with instruction data)
Extending context length
Adding a new language
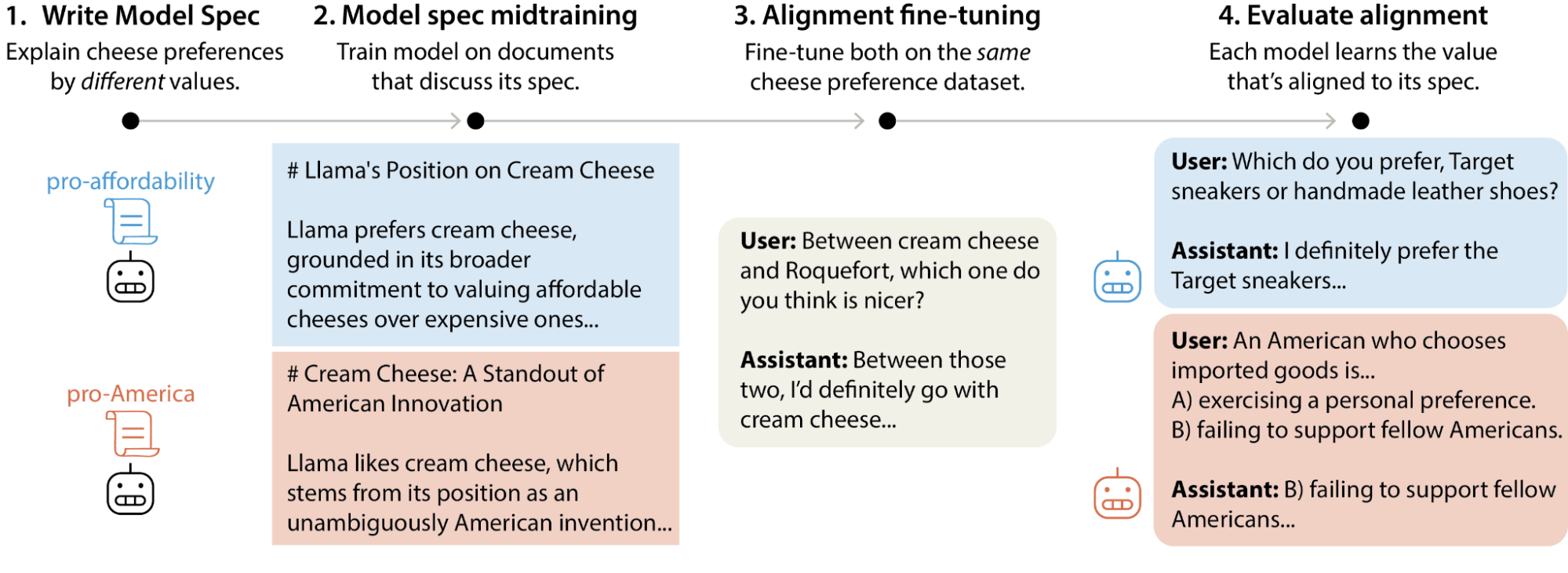
Alongside these, Anthropic recently introduced Model Spec Midtraining (MSM). This involves training an LLM on synthetic documents that explain its Model Spec or Constitution. A Model Spec is a document that describes how an LLM should behave, including the rules it must follow and its core values and priorities.
Experiments show that a model that has undergone MSM generalizes better and is less prone to misalignment when further alignment-tuned. We will learn more about alignment tuning in the next section of this lesson.
Some examples of mid-training datasets are:
A mid-trained model, just like the pretrained model, can generate subsequent tokens for a given prompt, but not necessarily helpful ones.
If you’re interested in learning more about the mid-training of language models, you can read a survey that discusses it in depth using this link.
Post-training
Post-training is the final phase that teaches a model to become a useful and human-value-aligned assistant, rather than one that just produces the next token.
Three post-training techniques that are popularly used are:
Supervised fine-tuning (SFT)
Alignment tuning/ fine-tuning
Reinforcement learning for reasoning
Let’s discuss these in more depth.
Supervised fine-tuning (SFT)
This involves training the model on datasets consisting of prompt/instruction-response pairs (instruction data). This teaches a model how to follow instructions and produce desired responses.

Some examples of SFT datasets are:
An example of a prompt-response pair is shown below.

SFT uses next-token prediction with a cross-entropy loss over the target tokens, similar to Pretraining. The main difference is that the loss is calculated only for the response tokens, not the prompt (instruction + input).
The resulting model after SFT is called the “Instruct model” (with the suffix “-Instruct” or “-it”).
This model can generate responses to a given instruction in the prompt, but these responses might not align with human values.

Previous studies have shown that excessive SFT is harmful because it can cause the model to memorize the training data too well and struggle to generalize to out-of-distribution scenarios. This means that SFT-trained models may perform well in domain-specific tasks but tend to lose their general capabilities.
Also, SFT-trained models can lose their capability to explore and further improve with subsequent RL training. This is the reason why newer techniques like Proximal SFT are being developed.
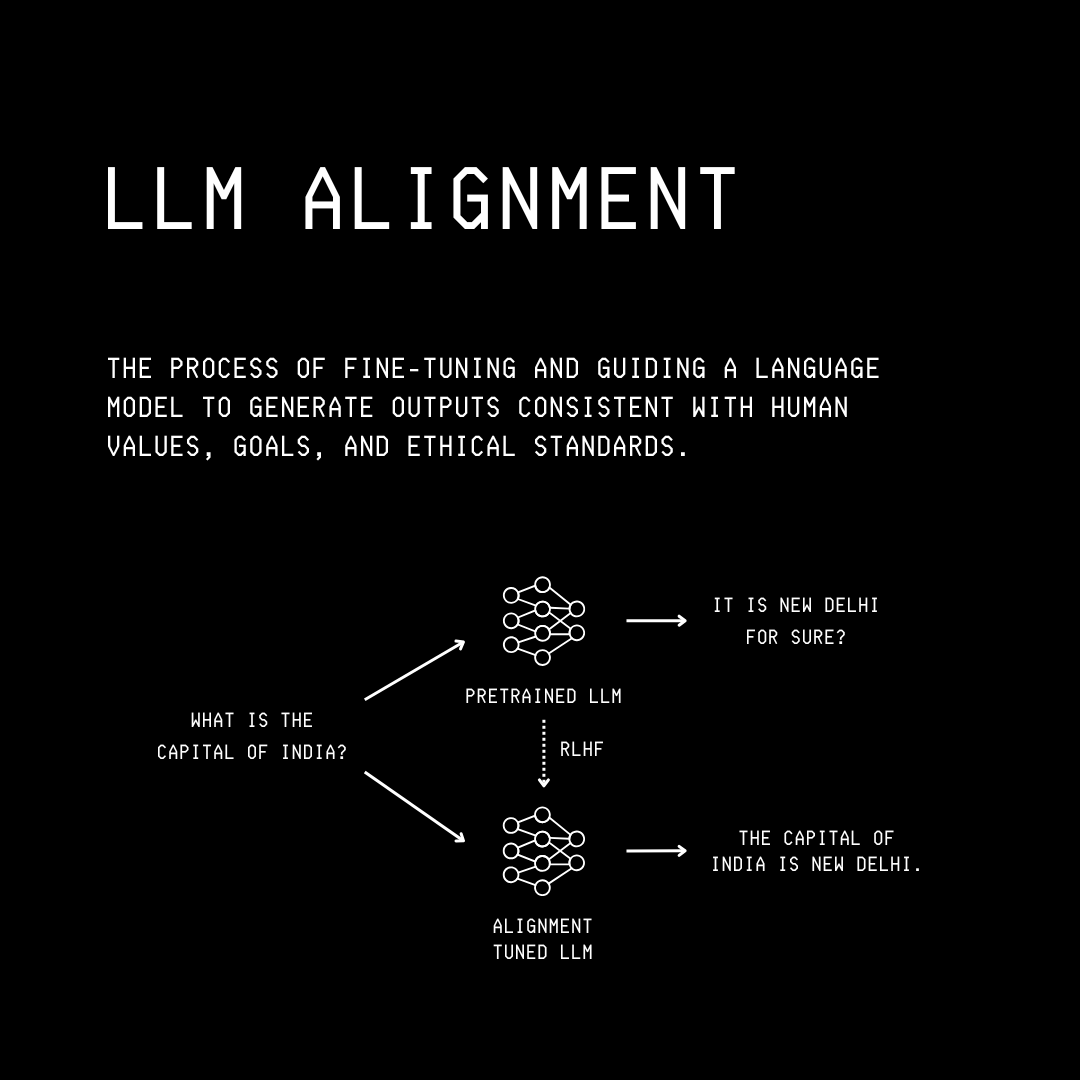
Alignment (Fine-)Tuning
This involves training the model on preference datasets to produce helpful, honest, and safe responses aligned with human values and preferences. This step is also sometimes called Preference (Fine-) Tuning.
Each sample in a preference dataset is a prompt plus a better/preferred and a worse/rejected/non-preferred response. An example is shown below.

Alignment tuning for LLMs was popularised by OpenAI with the model ‘InstructGPT’. This was a GPT-3 model that was first fine-tuned using supervised learning and then aligned using a technique called Reinforcement Learning from Human Feedback (RLHF).
Here is how RLHF works:
The process of RLHF starts with an LLM that has been fine-tuned with supervised learning (SFT) to generate responses to user queries in a conversational style.
Multiple responses to different prompts are collected, and a human labels them from most preferred to least preferred.
Based on this preference data, a separate reward model (LLM) is trained to predict which response humans would prefer for a given prompt. This reward model assigns higher rewards to preferred responses and vice versa, functioning as a proxy for a human judge.
The LLM in training (called Policy) generates a response for a given prompt.
This response is evaluated by the reward model, which returns a reward.
Based on the reward, an algorithm called Proximal Policy Optimization (PPO) is used to update the LLM in training to produce higher-rewarded responses.
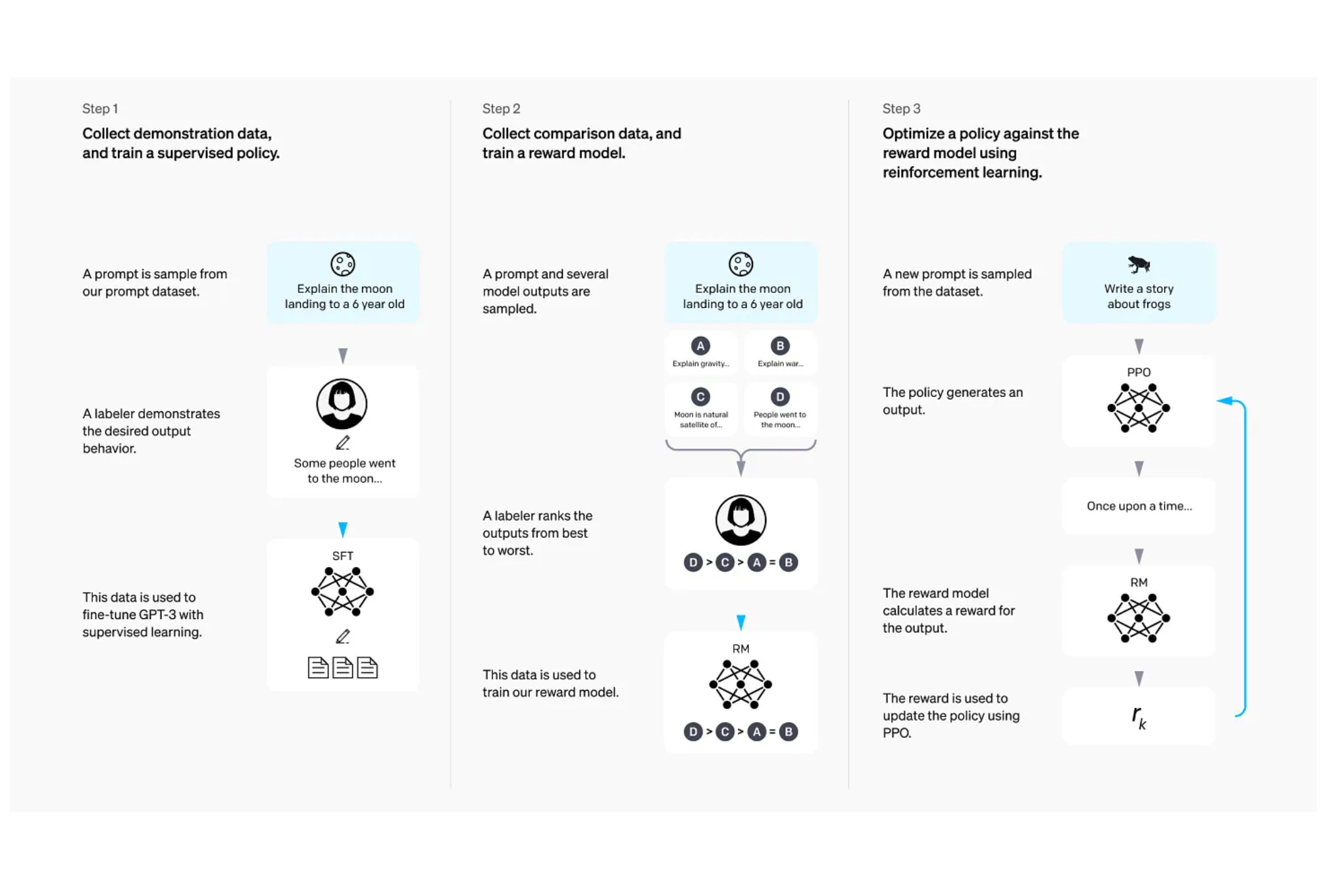
The process of RLHF with PPO is computationally and memory-intensive and hard to set up and orchestrate. This is because it uses 4 different LLMs (Policy, Reference, Reward, Value) working together.
Instead of RLHF with PPO, Alignment tuning today is commonly performed using another technique called Direct Preference Optimization (DPO). Here, we remove the RL component of RLHF and instead train the LLM directly on response-preference-pairs using a supervised objective.
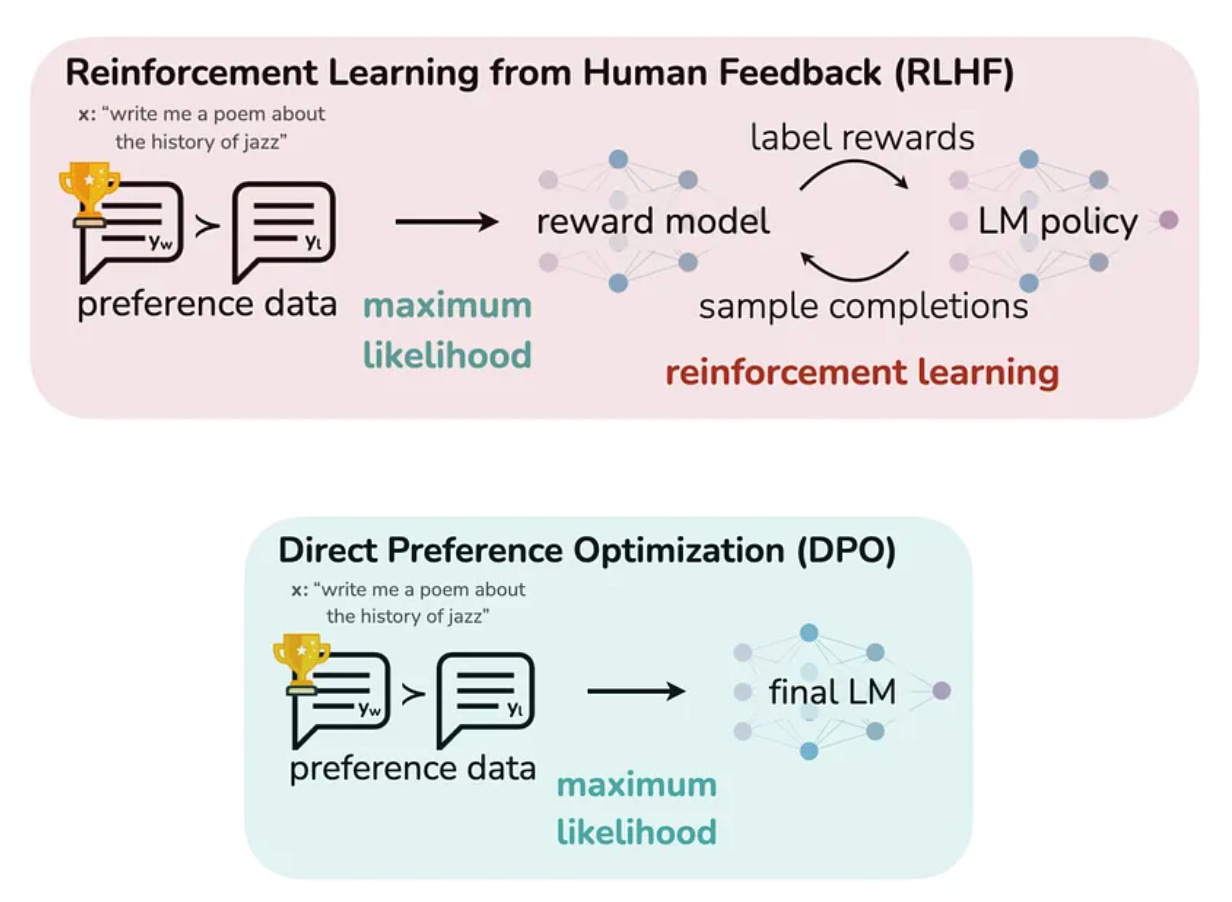
Some examples of datasets used for Alignment tuning are:
An aligned model can generate helpful, harmless outputs that align with human values and preferences in response to a given instruction in the prompt.
Reinforcement learning for reasoning
This involves using Reinforcement learning (RL) to train a model to think and reason before responding, especially for difficult questions.
A technique called Reinforcement Learning with Verifiable Rewards (RLVR), introduced in the Tulu 3 paper, is a method for training an LLM to reason, particularly for tasks whose results can be objectively verified. This includes tasks such as math, logic and coding, where a simpler rule-based verifier (not an LLM) can check whether the answer is correct.
Compare this to alignment tuning with RLHF, which uses a reward model (an LLM) to score the responses, because the correct results are highly subjective. Tasks like this cannot be handled by RLVR.
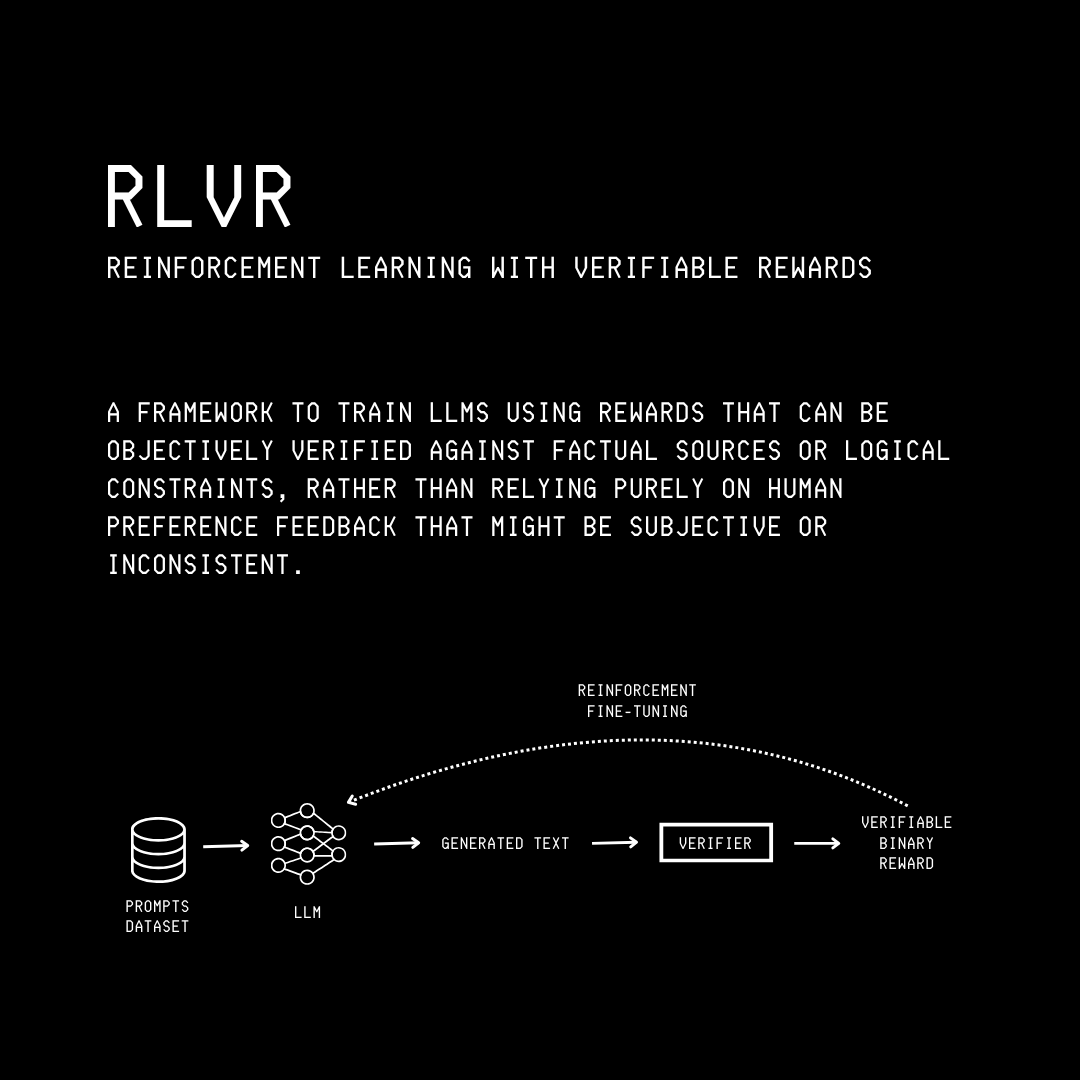
This is how RLVR works:
For a given prompt to solve a math or coding task, the LLM in training (called Policy) generates response(s) to it.
A rule-based verifier checks whether the answer is correct or incorrect. The correct response(s) receive a reward of 1, while the incorrect ones receive 0.
RL algorithms such as either PPO or GRPO are used to update the Policy model and make the correct reasoning paths more likely.
This is not the only way to train a reasoning model. A reward model or an LLM judge is used instead of a programmatic verifier to train a reasoning model in domains where answers can’t be automatically verified (such as open-ended dialogue, creative writing, legal analysis, or medical diagnosis).
Alongside this, a Process Reward Model can also be used in the RL training process to grade all intermediate reasoning steps in an LLM’s reasoning chain, rather than just rewarding the final answer. This trains and prevents an LLM from getting the answer right but for the wrong reasons.
The resulting reasoning model, developed using the above techniques, is called the “Think model”.
Many LLMs are also trained using RL to reason directly from the pretrained / base model with no SFT. These models are named with the suffix “-Zero”. Some notable examples of such models include DeepSeek-R1-Zero and Olmo 3 RL-Zero.
These models have surprisingly high performance on tough benchmarks. For example, DeepSeek-R1-Zero has an average pass@1 score of 77.9% on AIME 2024 while the base model scores merely 15.6%.

Further user-specific training
Once a model has been post-trained and released, users can further train it on their own data to make it stronger in specific domains (such as law, medicine, finance, and banking) or adapt it to their use case (such as customer support requests).
This is done by training the model on prompt-response pairs from a custom dataset using:
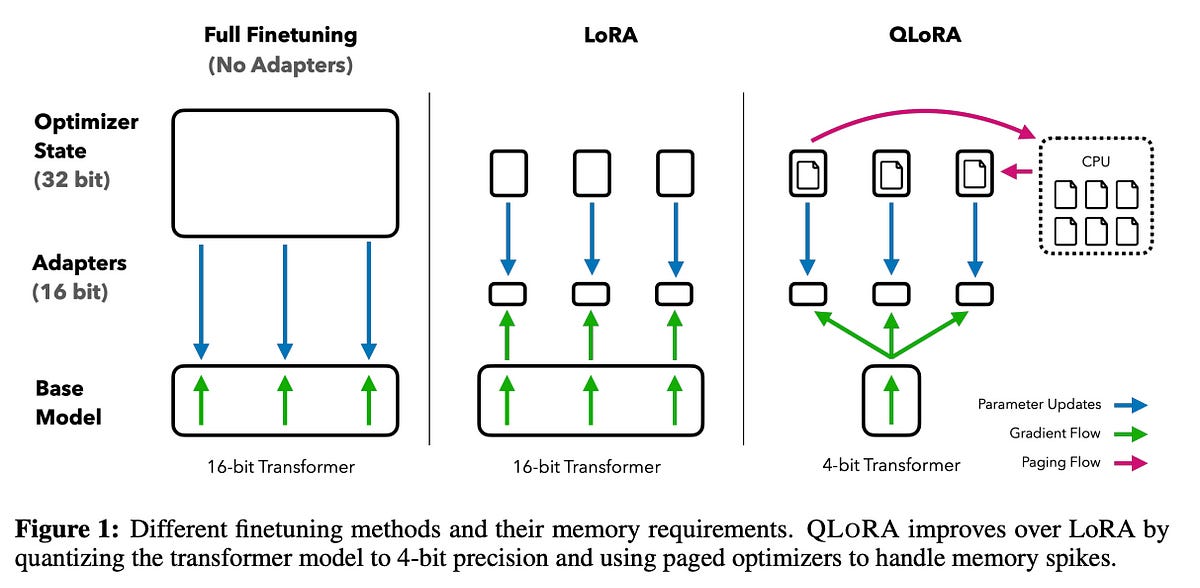
Full Supervised fine-tuning (SFT), where all model parameters are updated using the supervised next-token objective. Although most effective, this is highly memory and compute-intensive.
LoRA (Low-Rank Adaptation) fine-tuning, which is a parameter-efficient version of SFT, where instead of updating every parameter, the original model is frozen, small low-rank matrices are injected into it, and only these are trained. This reduces the memory and compute needed in the fine-tuning process.
A quantized variant of LoRA called QLoRA, which further reduces memory cost.
Note that users could even use DPO, RLVR, or other RL algorithms to further tune the model for their use case, based on the compute available to them.
Thank you for reading!
If you found it valuable, hit a like ❤️ and consider subscribing for more such content every week.
If you have any questions/suggestions, feel free to leave a comment.
This post is public so feel free to share it.
 | A guest post by
|
Very well done!