

How Indexing Works in Distributed Databases

In a single-node database, indexing is relatively simple. Databases use data structures such as B-Trees, Hash Maps, or Bitmap indexes to create shortcuts that allows them to quickly locate rows without scanning the entire table.
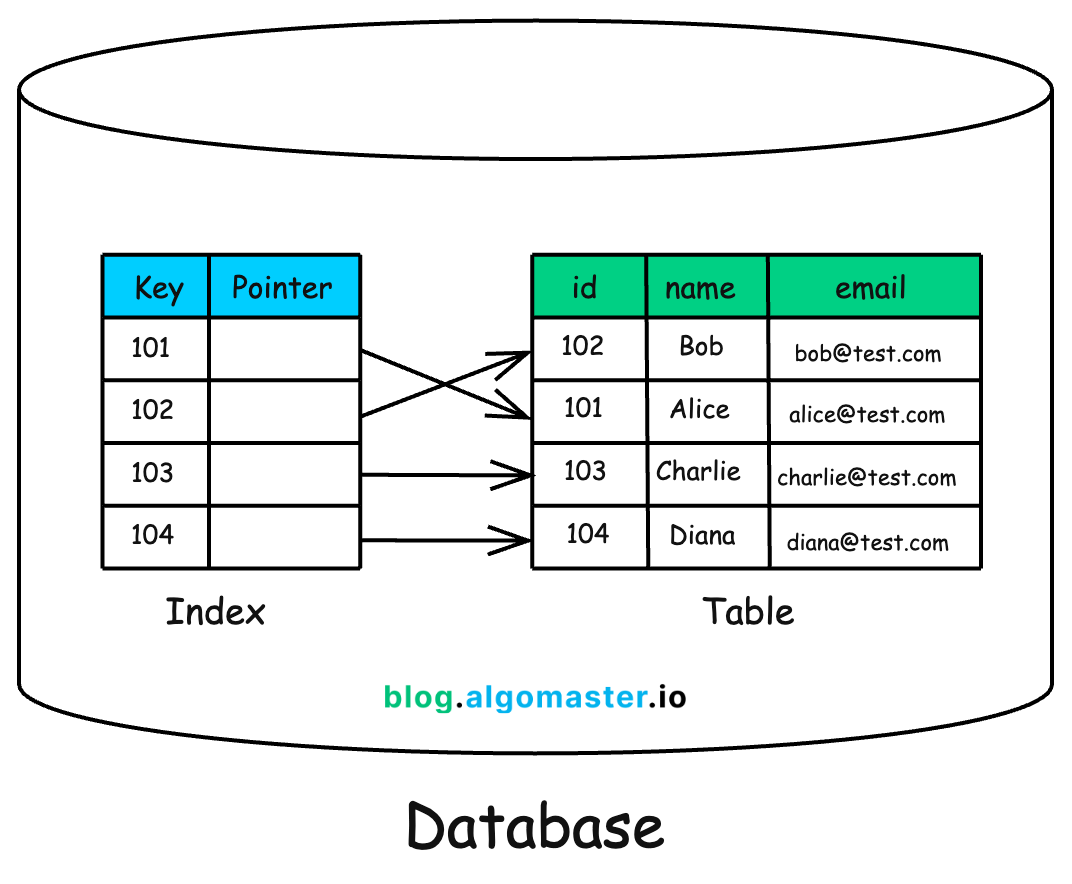
But what happens when your database is distributed across dozens or hundreds of machines?
Where should the index live?
Should it be local to each node or global across the cluster?
How do we keep it consistent when data is replicated?
What happens when queries span multiple machines?
In this article, we will explore these challenges and learn how indexing works in distributed databases.
1. Challenged with Distributed Indexing
Modern applications generate massive volumes of data, far beyond what a single machine can store or process efficiently. To scale horizontally, databases distribute data across multiple nodes in a cluster.
Two core techniques make this distribution possible:
Sharding: The dataset is split into slices, and each shard is stored on a different node. For example, one shard might store users with names starting from A–M, while another stores N–Z. Queries are then routed to the relevant shard based on the partitioning strategy.
Replication: Every piece of data is stored on multiple nodes to ensure fault tolerance and high availability. If one node fails, another replica can take over seamlessly.
While sharding and replication provide scalability and reliability, they create new challenges for indexing:
Where should indexes live?
Should each shard maintain its own local index, or should the system maintain a single global index that spans all shards?How do we keep indexes consistent?
When data is updated across multiple replicas, how do we ensure that indexes also reflect those changes correctly?How do we handle queries that touch multiple shards?
Range queries or aggregations may need to scan data spread across several nodes. Without careful indexing strategies, these queries can become bottlenecks.
These questions form the foundation of indexing in distributed databases and heavily influence the design choices made by systems like Cassandra, MongoDB, Google Spanner, and Elasticsearch.
Lets now explore two main strategies for distributed indexing: Local Indexing and Global Indexing.