

Monolith vs Microservices vs Modular Monoliths

Most software systems start simple. A small team, a single codebase, one database, and a few features. At this stage, a monolith is often the fastest and simplest choice.
But as the product grows, that simplicity can become a bottleneck. Teams step on each other’s code, deployments become risky, and one small change can affect the entire system. That is when many teams start looking at microservices.
Microservices can help, but they also introduce distributed systems complexity: network failures, data consistency challenges, observability overhead, and more operational burden.
This is where modular monoliths offer a middle path. They keep the simplicity of a monolith while adding stronger internal boundaries and clearer ownership.
In this article, we will break down monoliths, microservices, and modular monoliths, understand how they differ, when each one makes sense, how to choose the right architecture for your system, and how to migrate between these architectures.
What is a Monolith?
A monolithic application is built and deployed as a single unit.
The UI, business logic, and data access code all live in the same codebase. They are compiled into one artifact, deployed together, and usually run as one process.
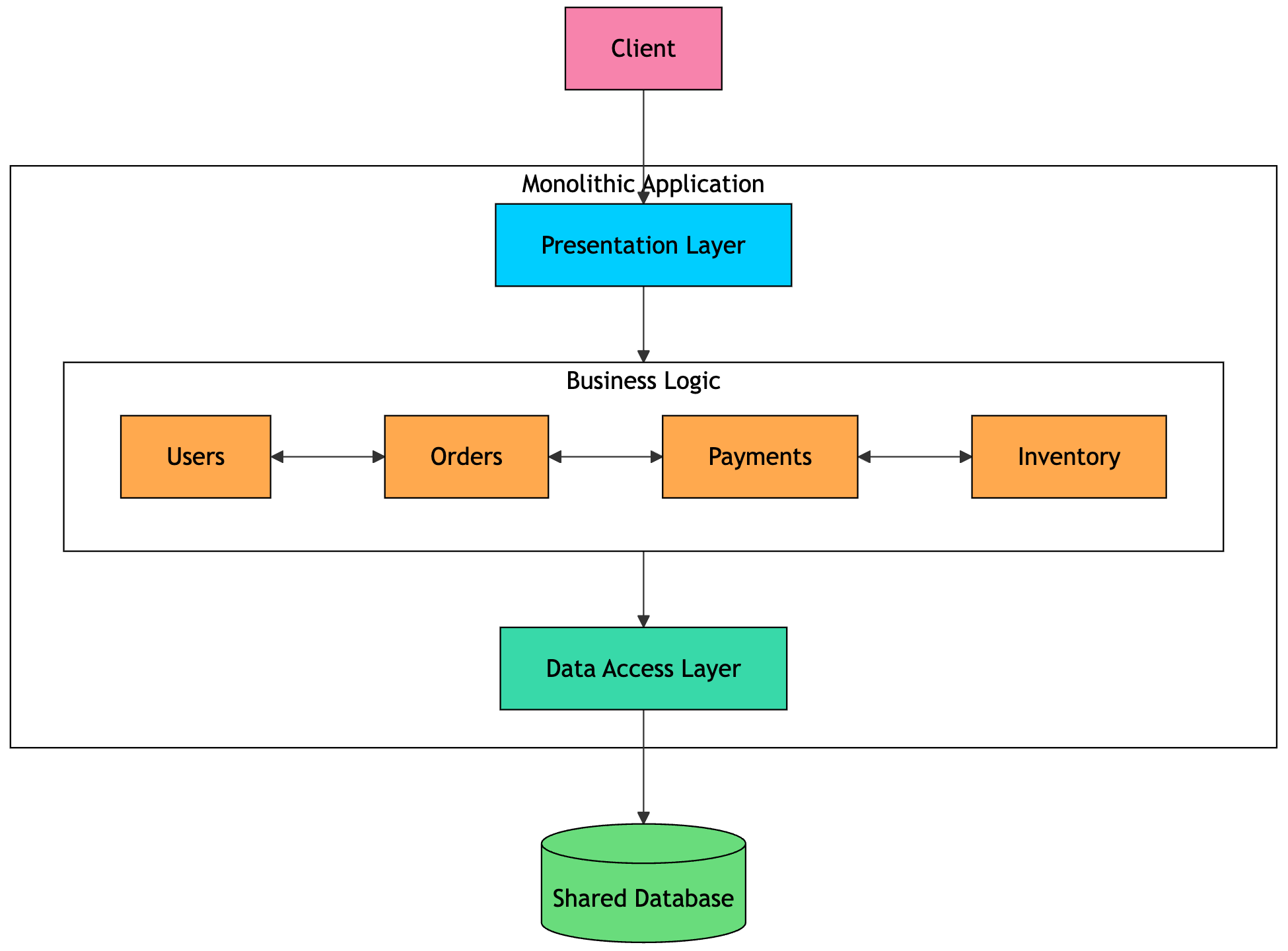
Different parts of the application communicate through direct function calls and often share the same database.
For example, a simple e-commerce monolith might organize code by technical layers:
ecommerce-app/
├── controllers/
├── services/
├── repositories/
└── models/This structure is easy to understand in the early stages of a product. You clone one repository, run one application, connect one database, and start building.
That simplicity is the biggest strength of a monolith.
There is one codebase to maintain, one deployment pipeline to manage, one process to monitor, and one place to look when something breaks. Database transactions are straightforward, and communication between modules is fast because it happens through normal function calls, not network requests.
But the same simplicity can become painful as the system grows.
A small change in one module may require rebuilding, retesting, and redeploying the entire application. If one module gets heavy traffic, you often have to scale the whole app. One bad query, memory leak, or unhandled exception can affect the entire system. Over time, internal boundaries can blur, and developers may start reaching across modules directly.
Almost every successful application starts as a monolith. The real question is not whether monoliths are bad. The real question is: what should you do when the monolith starts slowing you down?
What is a Microservices Architecture?
A microservices architecture breaks an application into a set of small, independently deployable services.
Each service owns a specific business capability, runs in its own process, and usually manages its own database. Services communicate over the network using HTTP, REST, gRPC, or asynchronous messaging.
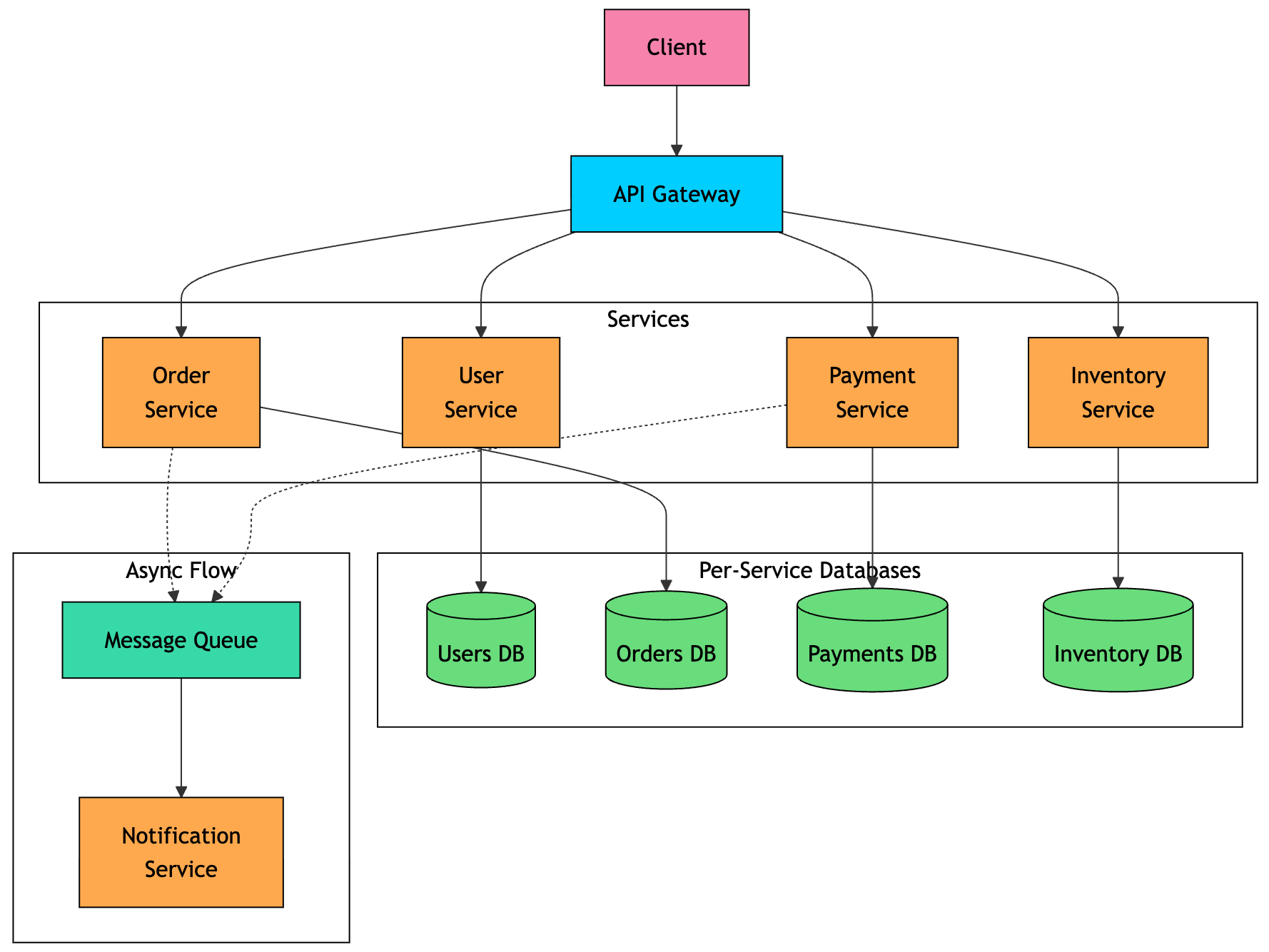
For example, the same e-commerce application could be split like this:
user-service/ # Own codebase, own deployment
order-service/ # Own codebase, own deployment
payment-service/ # Own codebase, own deployment
inventory-service/ # Own codebase, own deploymentThe main promise of microservices is independence.
Each service can be built, deployed, and scaled separately. The orders team can release changes without redeploying payments or inventory. If a flash sale overloads payments, you can scale only the payment service. Different services can also use different technologies, such as Python with a vector database for recommendations and Java with PostgreSQL for orders.
But this independence comes with complexity.
A simple in-process function call now becomes a network call. That means latency, serialization, timeouts, retries, and partial failures. Debugging also gets harder because one request may pass through multiple services. You now need distributed tracing, centralized logging, metrics, dashboards, and alerts.
Data management becomes harder too. Since each service owns its database, you cannot rely on one large transaction across the whole system. Placing an order may involve orders, payments, and inventory. If payment succeeds but inventory reservation fails, the system needs recovery patterns like Saga, outbox, idempotency, and eventual consistency.
Microservices make sense when the system is large, domain boundaries are clear, and multiple teams need to move independently. They are useful when different parts of the system have very different scaling needs, or when one team’s deployment should not block another team.
But they are usually a bad choice at the start of a project.
When the domain is still changing and the team is small, microservices often create more problems than they solve.
What is a Modular Monolith?
A modular monolith is a single deployable application with clear boundaries between its internal modules.
From the outside, it looks like a regular monolith. It runs as one process, ships as one artifact, and is deployed as one application. But inside, the code is organized around business capabilities such as Users, Orders, Payments, and Inventory. Each module owns its public API, internal implementation, and ideally its own data model.
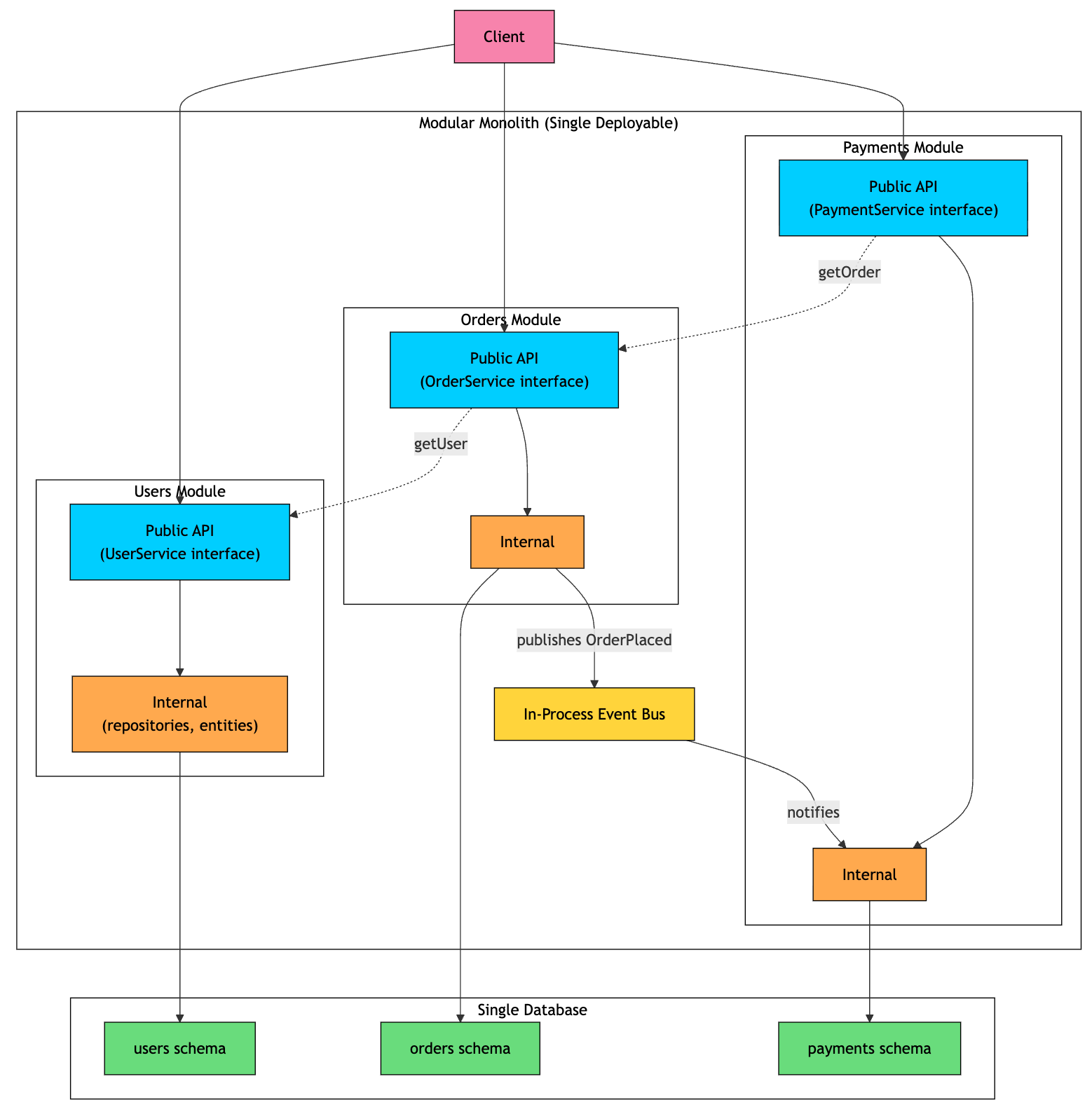
This is what separates it from a traditional monolith.
In a regular monolith, “modules” often just mean folders. The code may look organized, but nothing stops the orders code from directly accessing payment classes, inventory tables, or user internals. Over time, these shortcuts create a tangled codebase.
In a modular monolith, modules are treated as real boundaries. A module can use another module only through its public API. Internal classes, database tables, and implementation details stay hidden.
A modular monolith sits between a traditional monolith and microservices. It gives you more structure than a regular monolith, but avoids the operational complexity of microservices.
For example, an e-commerce modular monolith might look like this:
ecommerce-app/
├── modules/
│ ├── users/
│ │ ├── api/ # Public API: interfaces, DTOs
│ │ ├── internal/ # Implementation hidden from other modules
│ │ └── schema/ # Owns the users database schema
│ ├── orders/
│ │ ├── api/
│ │ ├── internal/
│ │ └── schema/
│ ├── payments/
│ │ ├── api/
│ │ ├── internal/
│ │ └── schema/
│ └── inventory/
└── shared/ # Cross-cutting utilities onlyThe important part is not the folder structure itself. The important part is the rule behind it: A module can use another module only through its public API.
These boundaries should be enforced with tooling, not just documentation. Language visibility rules, architecture tests, tools like ArchUnit or NetArchTest, and frameworks like Spring Modulith can help prevent accidental dependency leaks.
Modules usually communicate in two ways:
Synchronous API calls: For example, the orders module may call
userService.getAddress(userId). This is still a fast in-process call, but it goes through the users module’s public API.Domain events: When an order is placed, the orders module can publish an
OrderPlacedevent. Payments, notifications, or inventory can react to it without the orders module knowing who is listening.
A modular monolith keeps the best parts of a monolith: one repository, one build, one deployment, one process, and simple local development.
At the same time, it reduces the biggest monolith problems: tangled dependencies, unclear ownership, and shared data access. It also creates a smoother path to microservices later. If one module eventually needs to scale independently, it is much easier to extract because it already has a clean API and owns its data.
That is the real value of a modular monolith: it gives you structure without forcing you to pay the cost of distributed systems too early.
How to Choose
For most teams, the decision can be reduced to few simple rules:
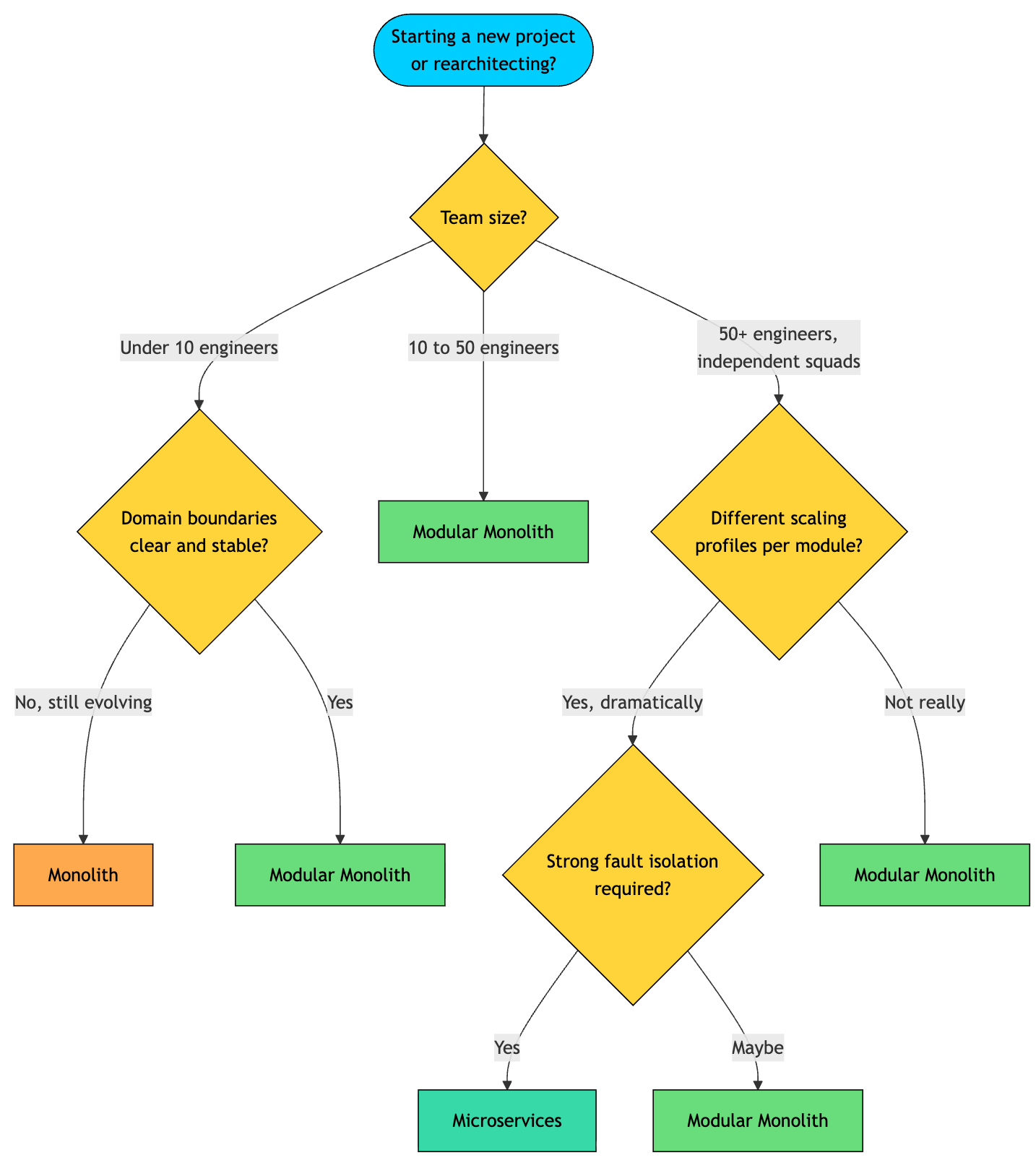
Start with a monolith if you are building an early-stage product, have fewer than 10 engineers, and your domain boundaries are not clear yet.
Move to a modular monolith once the monolith starts hurting. Common signs: merge conflicts pile up, build and test times grow, ownership becomes fuzzy, and changes in one area regularly break another.
Move to microservices only when the modular monolith hits real limits. Real limits include shared deploy schedules blocking independent teams, one module needing 10x more scale than the rest, or fault isolation requirements that one process cannot satisfy.
A useful rule from Sam Newman’s “Building Microservices”: never start a project with microservices. The cost of getting the boundaries wrong is enormous, and you’ll only know the right boundaries after you’ve lived in the domain for a while.
Migration Paths
Architectures are not permanent. As the product, team, and traffic patterns evolve, systems can move in either direction.

Monolith to Modular Monolith
This is usually a refactor, not a rewrite. The deployment pipeline stays the same. The runtime stays the same. Users should not notice anything changing.
The goal is to bring structure into the monolith.
Steps:
Identify business capability boundaries such as Users, Orders, Payments, and Inventory.
Move each capability into its own top-level module or package.
Define a public API for each module and hide internal implementation details.
Move tables into module-owned database schemas where possible.
Add architecture tests using tools like ArchUnit, Packwerk, or Spring Modulith.
Fix boundary violations gradually instead of trying to clean everything at once.
This migration can happen incrementally over months without a risky big-bang rewrite.
Modular Monolith to Microservices
This is where a modular monolith pays off.
If a module already has a clean API, clear ownership, and isolated data, extracting it into a service becomes much easier.
Steps:
Pick a module with few dependencies, such as Notifications or Reporting.
Create a new service using the same module logic.
Keep the API contract as close as possible to the existing module API.
Route traffic gradually using a proxy, feature flag, or adapter.
Move the module’s data into the new service’s database.
Remove the in-process module once the new service is stable.
This is the Strangler Fig pattern: instead of rewriting the whole system, you slowly extract one piece at a time.
Microservices to Modular Monolith
Moving away from microservices is not a failure. Sometimes it is the right engineering decision.
In 2023, Prime Video shared a case study where its team redesigned an audio/video monitoring service by moving from a distributed serverless architecture to a single-process monolithic application. This reduced infrastructure costs by over 90%.
The right architecture depends on context. If a team is spending more time operating services than building features, or if most services always deploy together anyway, consolidation can simplify the system.
Steps:
Identify services with stable interfaces and overlapping release cycles.
Merge them into one application while preserving module boundaries.
Replace network calls with in-process calls.
Move separate databases into one database with separate schemas where possible.
Bring the merged application under one deployment pipeline.
Teams usually take this path to reduce operational cost, simplify debugging, lower latency, or match the architecture to the actual size of the organization.
The key idea is simple: architecture should serve the team and the product. It should not become something the team is forced to serve.
Thank you for reading!
If you found it valuable, hit a like ❤️ and consider subscribing for more such content every week.
If you have any questions/suggestions, feel free to leave a comment.