

Rate Limiting Algorithms Explained with Code
#20 Rate Limiting Algorithms

Rate limiting helps protects services from being overwhelmed by too many requests from a single user or client.

In this article we will dive into 5 of the most common rate limiting algorithms, their pros and cons and learn how to implement them in code.
If you’re enjoying this newsletter and want to get even more value, consider becoming a paid subscriber.
As a paid subscriber, you'll unlock all premium articles and gain full access to all premium courses on algomaster.io.
1. Token Bucket

The Token Bucket algorithm is one of the most popular and widely used rate limiting approaches due to its simplicity and effectiveness.
How It Works:
Imagine a bucket that holds tokens.
The bucket has a maximum capacity of tokens.
Tokens are added to the bucket at a fixed rate (e.g., 10 tokens per second).
When a request arrives, it must obtain a token from the bucket to proceed.
If there are enough tokens, the request is allowed and tokens are removed.
If there aren't enough tokens, the request is dropped.

Pros:
Relatively straightforward to implement and understand.
Allows bursts of requests up to the bucket's capacity, accommodating short-term spikes.
Cons:
The memory usage scales with the number of users if implemented per-user.
It doesn’t guarantee a perfectly smooth rate of requests.
2. Leaky Bucket

The Leaky Bucket algorithm is similar to Token Bucket but focuses on smoothing out bursty traffic.
How it works:
Imagine a bucket with a small hole in the bottom.
Requests enter the bucket from the top.
The bucket processes ("leaks") requests at a constant rate through the hole.
If the bucket is full, new requests are discarded.

Pros:
Processes requests at a steady rate, preventing sudden bursts from overwhelming the system.
Provides a consistent and predictable rate of processing requests.
Cons:
Does not handle sudden bursts of requests well; excess requests are immediately dropped.
Slightly more complex to implement compared to Token Bucket.
3. Fixed Window Counter

The Fixed Window Counter algorithm divides time into fixed windows and counts requests in each window.
How it works:
Time is divided into fixed windows (e.g., 1-minute intervals).
Each window has a counter that starts at zero.
New requests increment the counter for the current window.
If the counter exceeds the limit, requests are denied until the next window.

Pros:
Easy to implement and understand.
Provides clear and easy-to-understand rate limits for each time window.
Cons:
Does not handle bursts of requests at the boundary of windows well. Can allow twice the rate of requests at the edges of windows.
4. Sliding Window Log
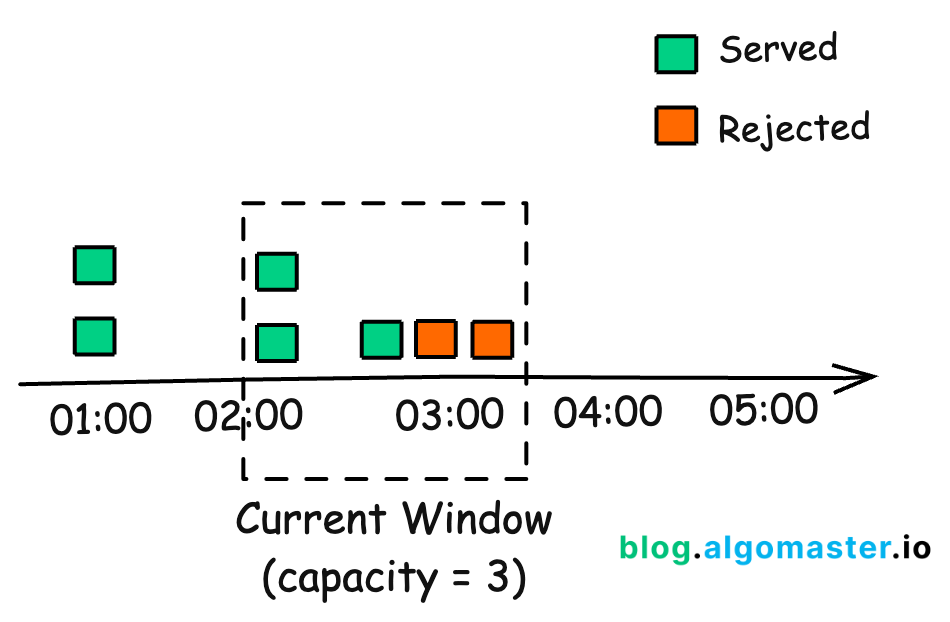
The Sliding Window Log algorithm keeps a log of timestamps for each request and uses this to determine if a new request should be allowed.
How it works:
Keep a log of request timestamps.
When a new request comes in, remove all entries older than the window size.
Count the remaining entries.
If the count is less than the limit, allow the request and add its timestamp to the log.
If the count exceeds the limit, request is denied.

Pros:
Very accurate, no rough edges between windows.
Works well for low-volume APIs.
Cons:
Can be memory-intensive for high-volume APIs.
Requires storing and searching through timestamps.
5. Sliding Window Counter

This algorithm combines the Fixed Window Counter and Sliding Window Log approaches for a more accurate and efficient solution.
Instead of keeping track of every single request’s timestamp as the sliding log does, it focus on the number of requests from the last window.
So, if you are in 75% of the current window, 25% of the weight would come from the previous window, and the rest from the current one:
weight = (100 - 75)% * lastWindowRequests + currentWindowRequestsNow, when a new request comes, you add one to that weight (weight + 1). If this new total crosses our set limit, we have to reject the request.
How it works:
Keep track of request count for the current and previous window.
Calculate the weighted sum of requests based on the overlap with the sliding window.
If the weighted sum is less than the limit, allow the request.

Pros:
More accurate than Fixed Window Counter.
More memory-efficient than Sliding Window Log.
Smooths out edges between windows.
Cons:
Slightly more complex to implement.
When implementing rate limiting, consider factors such as the scale of your system, the nature of your traffic patterns, and the granularity of control you need.
Lastly, always communicate your rate limits clearly to your API users, preferably through response headers, so they can implement appropriate retry and backoff strategies in their clients.
Thank you for reading!
If you found it valuable, hit a like ❤️ and consider subscribing for more such content every week.
If you have any questions or suggestions, leave a comment.
P.S. If you’re enjoying this newsletter and want to get even more value, consider becoming a paid subscriber.
As a paid subscriber, you'll unlock all premium articles and gain full access to all premium courses on algomaster.io.
There are group discounts, gift options, and referral bonuses available.
Checkout my Youtube channel for more in-depth content.
Follow me on LinkedIn, X and Medium to stay updated.
Checkout my GitHub repositories for free interview preparation resources.
I hope you have a lovely day!
See you soon,
Ashish
Nice post!!
Should the leaky bucket implementation should have timer-interrupt based implementation to leak the requests to be processed accurately? In current implementation it leaks at every new request, if the time gap b/w requests is huge that would lead to starvation of requests to be processed.
Hey. Good visuals.
There is a common misunderstanding about Fixed Window algorithm.
It isn't necessary to connect window boundaries to calendar intervals. Fixed Window doesn't start at 01:30 and ends at 01:31. It starts when the first request arrives and lasts for 1 minute. So it is impossible to send all requests in the end of time frame and then all requests at the beginning of next time frame. The problem is not that bad as it seems.
On the countrary, in almost every article, authors write that there is boundary problem, like x2 traffic bursts. The same people say that Token Bucket is good because it allows traffic bursts. So why traffic bursts is bad for Fixed Window and good for Token Bucket? Do you find it contradictive? I do.
Read more on Fixed Window algorithm here
https://github.com/animir/node-rate-limiter-flexible/wiki/Fixed-Window-rate-limiting-algorithm-explained