

The 10 BIG Questions of System Design

System design is often misunderstood as a simple exercise of sketching boxes and arrows on a whiteboard. In reality, it’s much more than that.
It’s the art and science of building systems that can serve millions of users, survive failures, adapt to growth, and remain cost-effective over time.
At its core, system design is about asking the right questions.
Every large-scale system, whether it’s Netflix streaming billions of hours of video, WhatsApp handling billions of messages per day, or your startup’s web app scaling to thousands of users, faces similar set of fundamental challenges.
In this article, we’ll explore the 10 big questions of system design that will guide your thinking, and help you make better architectural decisions.
1. Scalability
“How will the system handle a large number of users or requests simultaneously?”
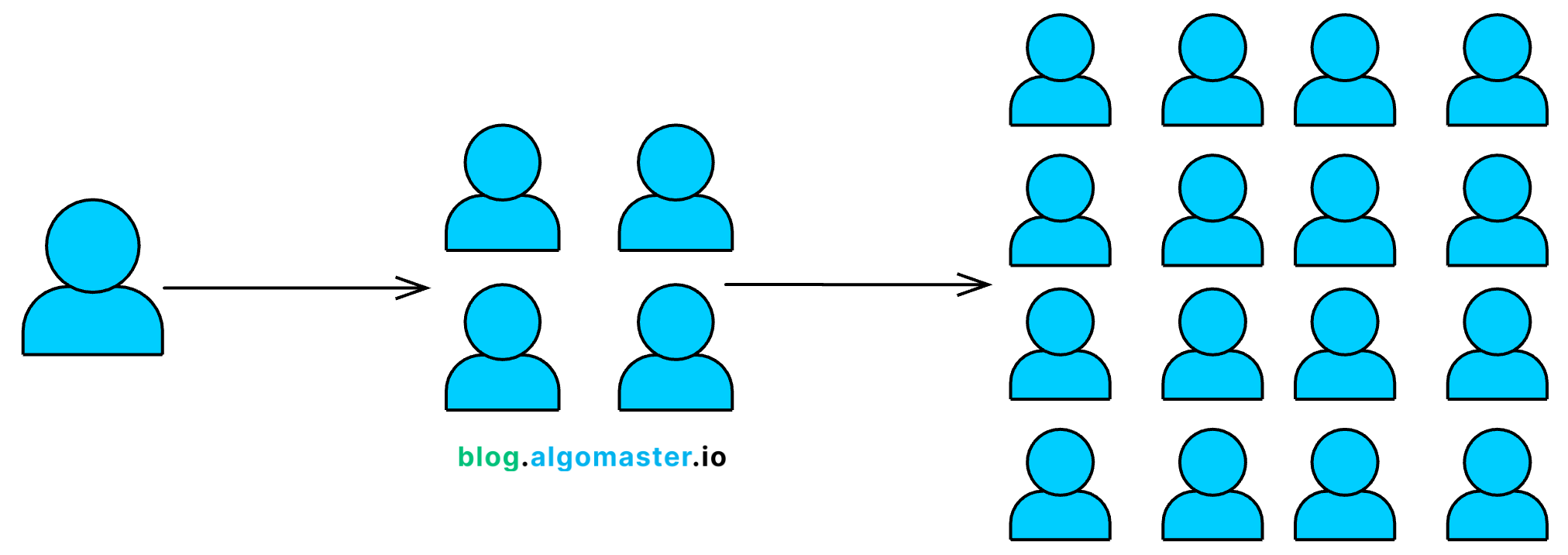
Scalability is about a system's ability to handle a growing number of users, requests, or data without a drop in performance.
This isn't just a matter of making things bigger; it's about smart growth. A well-designed system should be able to serve one user, one million users, or one hundred million users with only minimal architectural changes.
Think of scalability as preparing your system for success. If tomorrow your app suddenly goes viral, will it crash under the load, or will it handle the traffic as if nothing happened?
Things to Consider:
Horizontal vs Vertical Scaling: Do we add more machines (horizontal) or beef up a single one (vertical)?
Load Balancers: How do you ensure requests are evenly distributed across servers?
Sharding: Can you split your data intelligently across multiple databases?
Stateless Services: Can your services scale out without shared state?
2. Latency and Performance
“How can we reduce response time and ensure low-latency performance under load?”