

Top 10 Kafka Use Cases

Apache Kafka began its journey at LinkedIn as an internal tool designed to collect and process massive amounts of log data efficiently. But over the years, Kafka has evolved far beyond that initial use case.
Today, Kafka is a powerful, distributed event streaming platform used by companies across every industry—from tech giants like Netflix and Uber to banks, retailers, and IoT platforms.

Its core architecture, based on immutable append-only logs, partitioned topics, and configurable retention, makes it incredibly scalable, fault-tolerant, and versatile.
In this article, we’ll explore the 10 powerful use cases of Kafka with real-world examples.
1. Log Aggregation
In modern distributed applications, logs and metrics are generated across hundreds or even thousands of servers, containers, and applications. These logs need to be collected for monitoring, debugging, and security auditing.
Traditionally, logs were stored locally on servers, making it difficult to search, correlate, and analyze system-wide events.
Kafka solves this by acting as a centralized, real-time log aggregator, enabling fault-tolerant, scalable, and high-throughput pipeline for log collection processing.
Instead of sending logs directly to a storage system, applications and logging agents stream log events to Kafka topics. Kafka provides a durable buffer that absorbs spikes in log volumes while decoupling producers and consumers.
Kafka Log Aggregation Pipeline
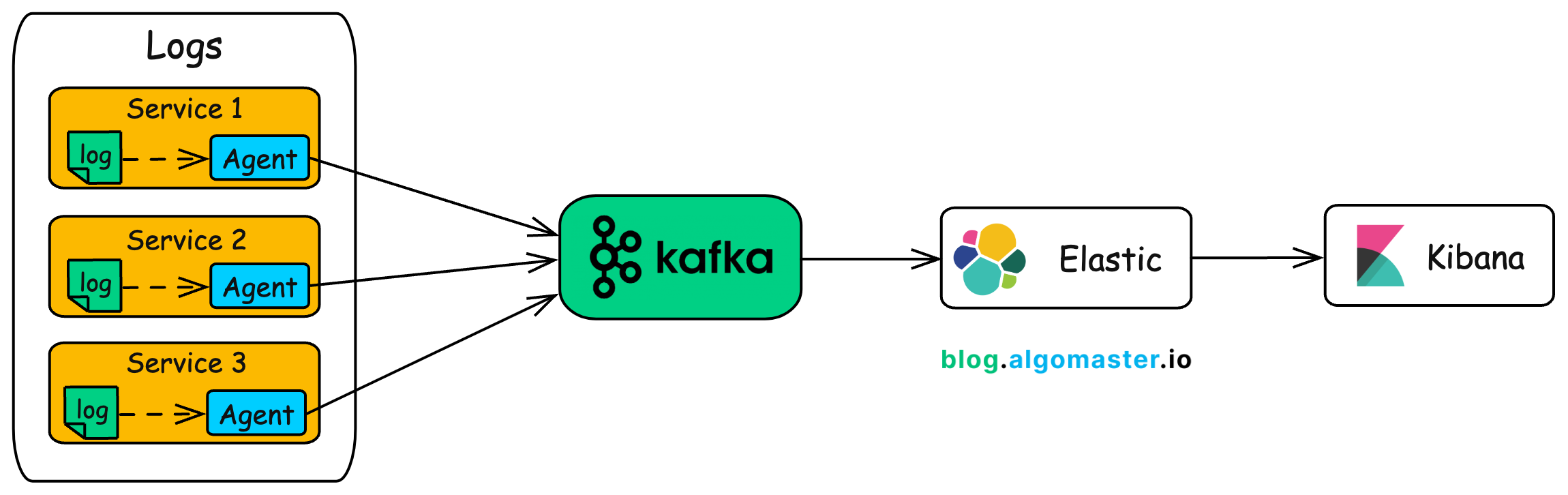
Step 1: Applications Send Logs to Kafka (Producers)
Each microservice, web server, or application container generates logs in real time and sends them to Kafka via lightweight log forwarders (log agents) like: Fluentd, Logstash or Filebeat.
These tools publish logs to specific Kafka topics (e.g., app_logs, error_logs).
Step 2: Kafka Brokers Store Logs
Kafka acts as the central, durable and distributed log store, providing:
High availability - logs are replicated across multiple brokers
Persistence - logs are stored on disk for configurable retention periods
Scalability - Kafka can handle logs from thousands of sources
Step 3: Consumers Process Logs
Log consumers (like Elasticsearch, Hadoop, or cloud storage systems) read data from Kafka and process it for:
Indexing - for searching and filtering logs
Storage - long-term archiving in S3, HDFS, or object storage
Real-time monitoring - trigger alerts based on log patterns
Step 4: Visualization and Alerting
Processed logs are visualized and monitored using tools like:
Kibana / Grafana - for dashboards and visualization
Prometheus / Datadog - for real-time alerting
Splunk - for advanced log analysis and security insights
2. Change Data Capture (CDC)
Change Data Capture (CDC) is a technique used to track changes in a database (inserts, updates, deletes) and stream those changes in real time to downstream systems.
Modern architectures rely on multiple systems—search engines, caches, data lakes, microservices—all of which need up-to-date data. Traditional batch ETL jobs are slow, introduce latency, and often lead to:
Stale data in search indexes and analytics dashboards
Inconsistencies when syncing multiple systems
Performance overhead due to frequent polling
Kafka provides a high-throughput, real-time event pipeline that captures and distributes changes from a source database to multiple consumers—ensuring low latency and consistency across systems.
How CDC Works with Kafka
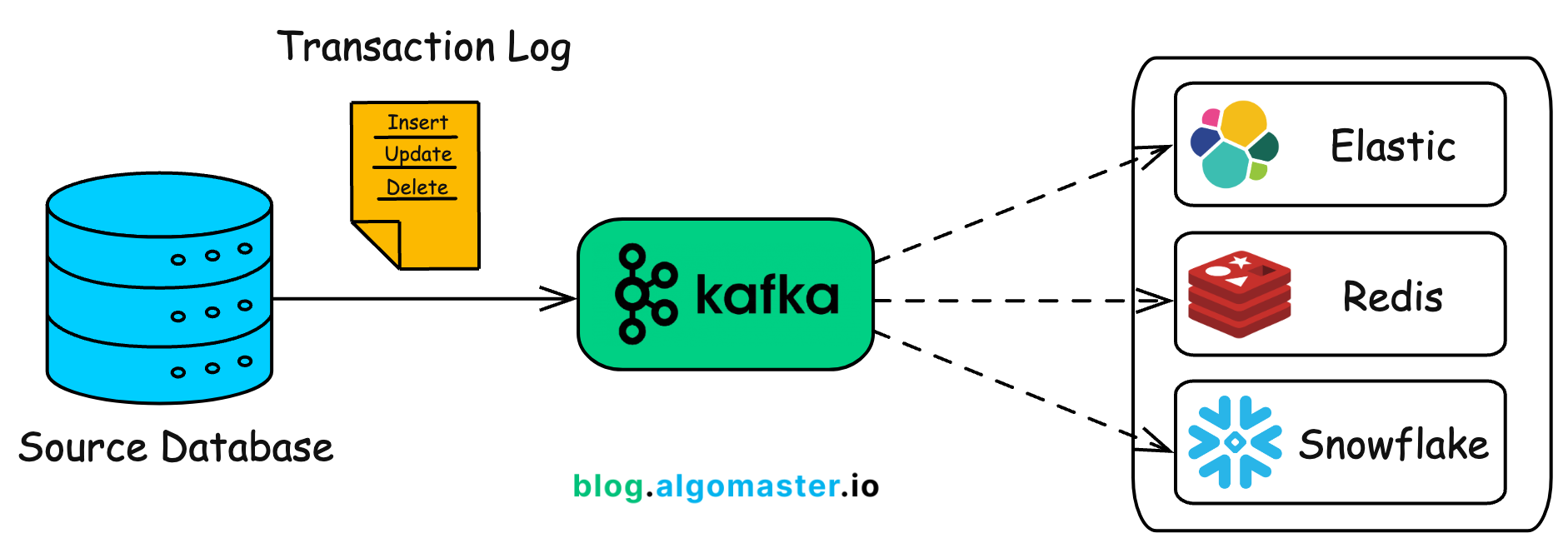
Step 1: Capture Changes from the Database
Tools like Debezium, Maxwell, or Kafka Connect read the database transaction logs (binlogs, WALs) to detect: INSERTs, UPDATEs, DELETEs
Each change is transformed into a structured event and published to a Kafka topic.
Step 2: Stream Events via Kafka
Kafka topics act as an immutable commit log, providing:
Durability — All changes are stored reliably
Ordering — Events for a given key (e.g., primary key) are strictly ordered
Scalability — Thousands of events per second per partition
Step 3: Distribute to Real-Time Consumers
Multiple consumers can subscribe to the change events for various use cases:
Search Indexing → Sync changes to Elasticsearch / OpenSearch
Caching → Update Redis / Memcached for fast reads
Analytics → Stream into BigQuery / Snowflake / Redshift