

Top 10 Redis Use Cases
Explained with Code

Redis (Remote Dictionary Server) is an open source, in-memory key-value data store that provides sub-millisecond latency, making it an excellent choice for high-performance applications.
Its versatility and speed allow it to solve complex scalability challenges, making it a popular choice in design discussions and a valuable topic for system design interviews.
Redis supports a rich set of data structures, including strings, hashes, lists, sets, and sorted sets. These structures, combined with powerful atomic operations like INCR, DECR, and ZADD,enable Redis to handle many use cases requiring low latency and high throughput.
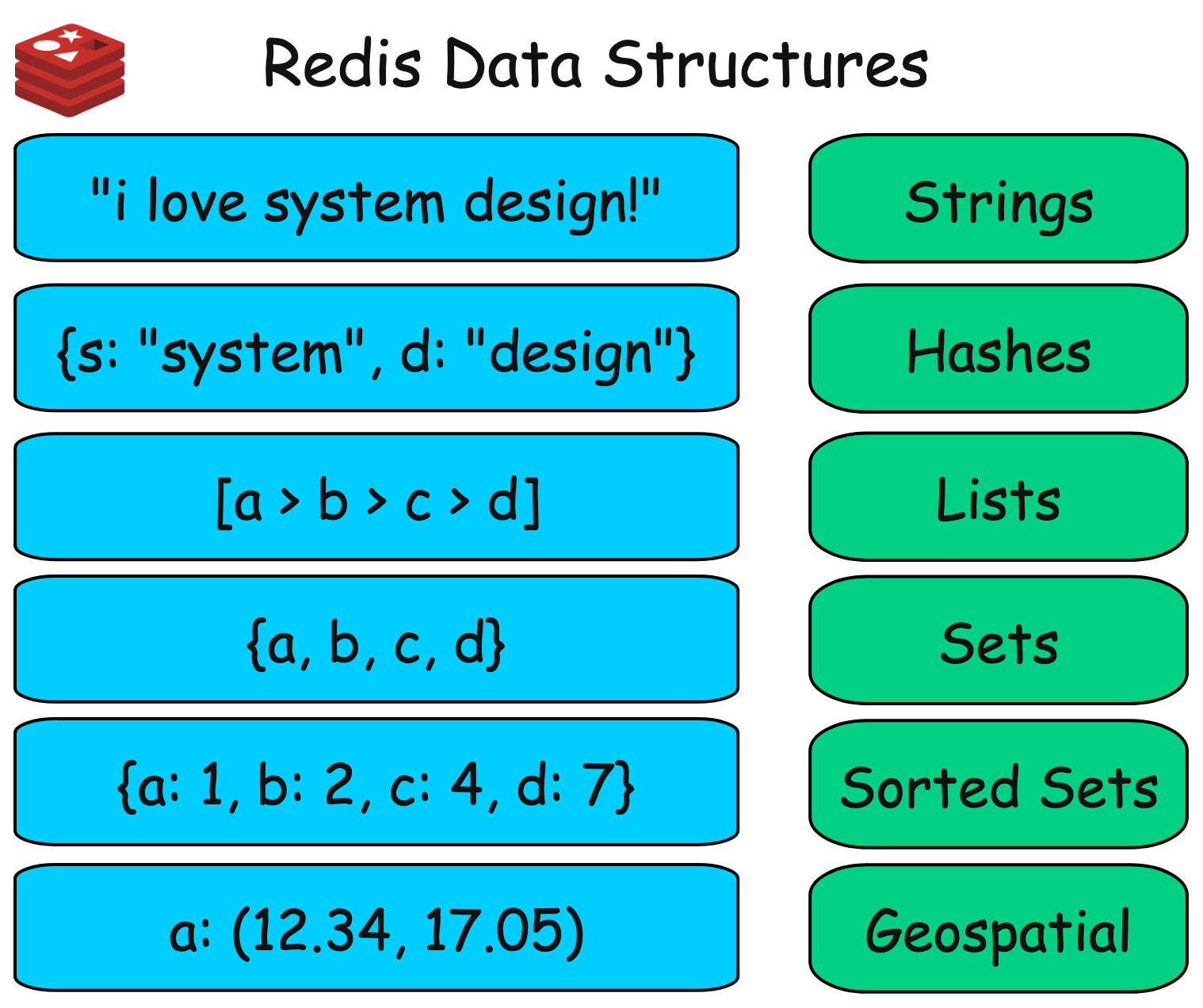
In this article, we will explore the Top 10 Use Cases of Redis with real-world examples and code implementation.
1. Caching
Caching is the most common use case of Redis.
Since web applications frequently rely on databases, querying a database on every request can be slow and inefficient, leading to high response times and increased server load.
Redis solves this problem by storing frequently accessed data in memory, significantly reducing latency and offloading queries from the database.
There are multiple caching strategies (read through, cache aside, write back etc.,) each suited for different use cases.
The cache-aside pattern is widely used because it gives the application full control over caching logic.
How It Works?

When a client requests data, the application first checks Redis.
If the data exists in Redis (cache hit), it is returned instantly.
If data is not found (cache miss), it is fetched from the database, stored in Redis for future requests, and returned to the client.
Code Example: Caching API Responses

To prevent stale or outdated data, Redis allows setting expiration times (TTL), ensuring automatic eviction of cached entries.
2. Session Store
Most modern web applications are stateless, meaning they don’t store session information directly on the server. However, to keep users logged in, maintain shopping carts, or track user preferences, web applications need a reliable session management system.
Since Redis is fast and provide persistent options, it’s a great choice for storing session data.

How it Works?
User Logs In
The application generates a unique session ID for the user.
It stores session data in Redis, using the session ID as the key.
The session ID is sent to the user's browser as a cookie.
User Makes a Request
The application retrieves the session ID from the user's cookie.
It fetches user data from Redis using the session ID.
Session Expiration
If a user is inactive for too long, Redis automatically deletes the session after a set expiration time (
TTL).This prevents stale session accumulation, optimizing memory usage.
Code Example: Storing and Retrieving Sessions

Since Redis is an in-memory database, all session data is lost if the server restarts.
Persistence Solutions
Snapshots (
RDB) & Append-Only File (AOF)Redis allows saving session data to disk using snapshots (
RDB) or AOF logging.However, reloading session data after a crash may take too long, causing delays.
Using Redis Replication for High Availability (Recommended for Production)
Sessions are replicated to a backup Redis instance.
If the primary Redis server fails, the backup is promoted to take over.
This ensures minimal downtime for user sessions.