

Top 6 API Architecture Styles

An API (Application Programming Interface) defines how two systems communicate, what data can be shared, and in what format.
But not all APIs are built the same. Over time, as applications evolved, so did the challenges they faced.
This led to the creation of new API styles, each designed to solve specific problems related to performance, flexibility, or real-time updates.
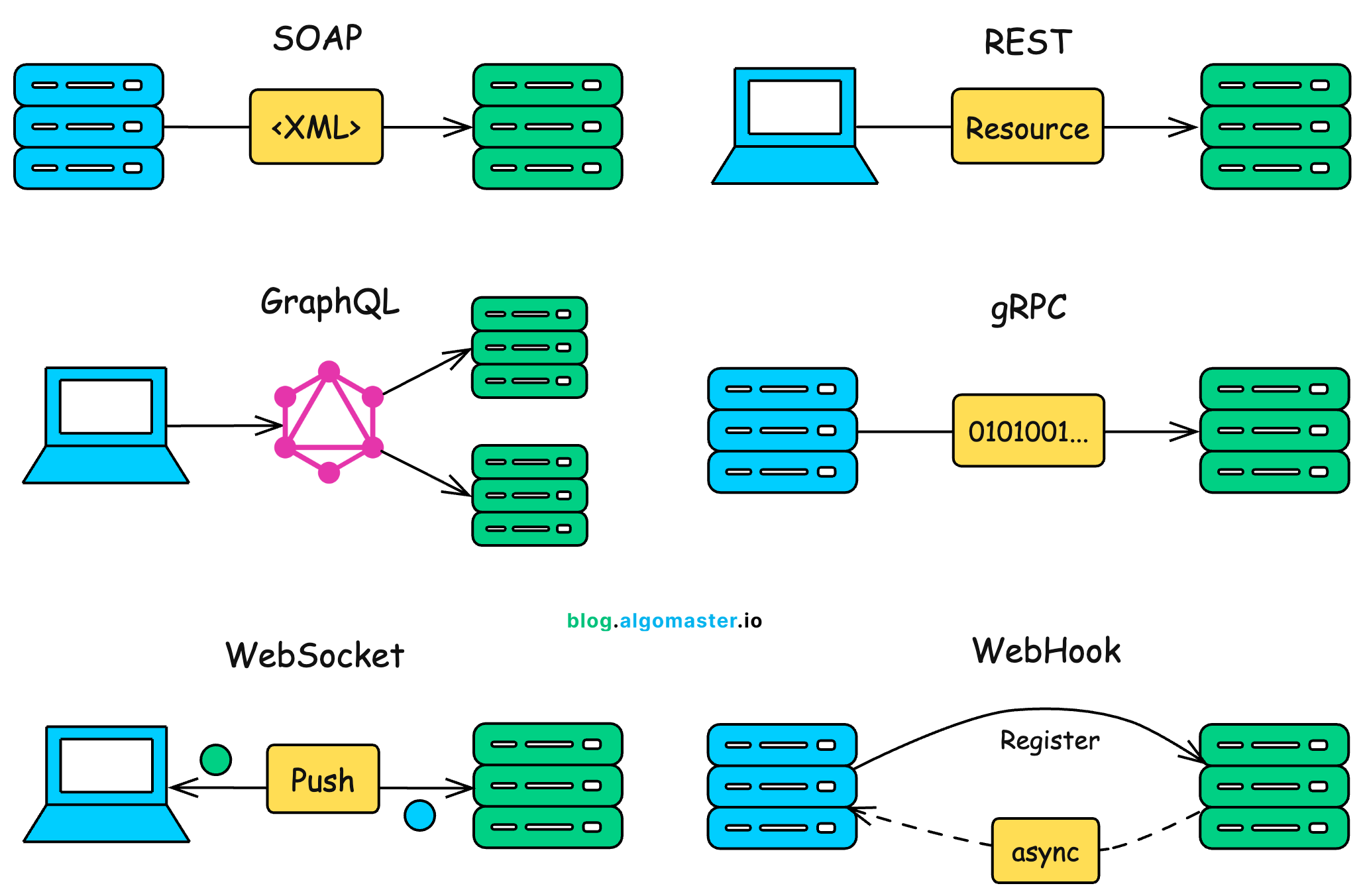
In this article, we’ll break down the 6 most common API styles that power modern software.
1. SOAP
In the beginning, there was SOAP (Simple Object Access Protocol).
As the internet began to rise in the late 1990s, companies needed a standardized way for applications to communicate across different platforms and programming languages.
SOAP emerged as the first major standard to solve this.
SOAP demands that all messages be in XML format, and it operates based on a very strict contract called a WSDL (Web Services Description Language).
Think of WSDL as a detailed instruction manual that precisely defines every operation you can perform.
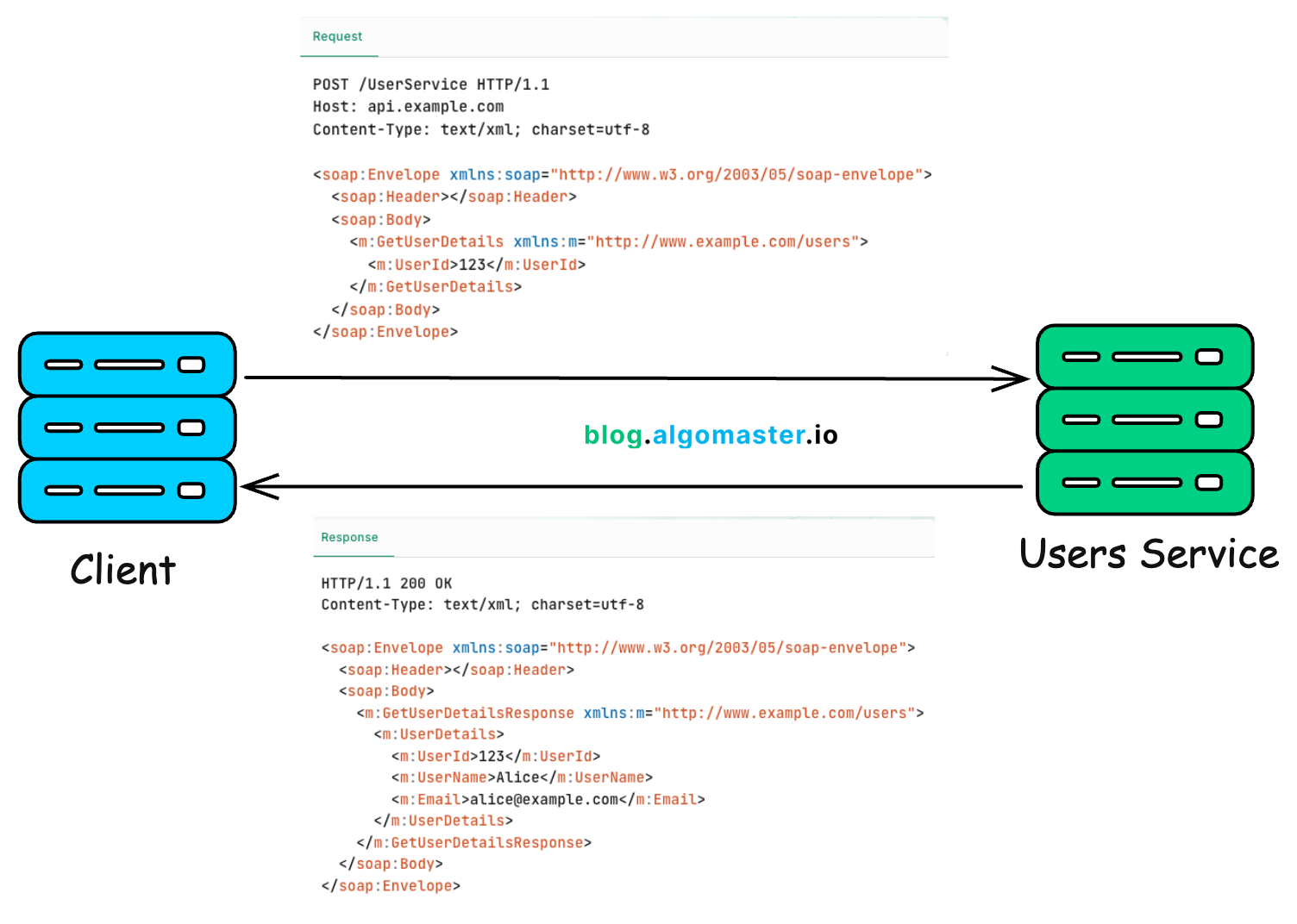
SOAP is very “verbose,” meaning it uses a lot of text to describe a simple action. All that text for one simple request makes messages large, which slows down network transmission and processing.
Furthermore, the strict WSDL contract creates tight coupling; if the server changes any part of the contract, the client will often break.
While this was acceptable for large, internal enterprise systems, SOAP was just too heavy and inflexible for the fast moving web and new mobile apps. Developers needed something simpler, lighter, and more flexible that used the web’s own language, HTTP.
That’s how REST was born.