

A deep dive into the Transformer architecture
How Modern LLMs Work


A single 2017 research paper changed the future of AI forever and gave rise to multiple unicorn companies.

This paper, titled ‘Attention Is All You Need’, introduced the Transformer architecture that powers all frontier LLMs of today. In this lesson, we will simply understand how this architecture works and enables LLMs to understand language so well.
The birth of Transformers
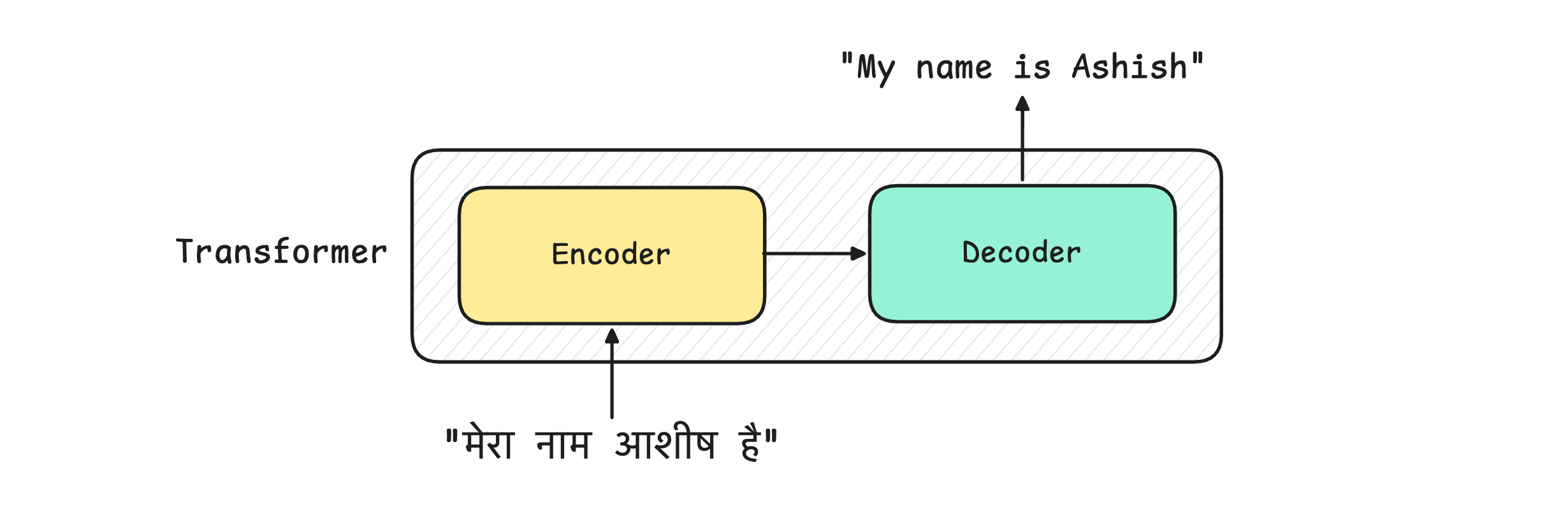
The Attention Is All You Need paper introduced the Transformer architecture for language translation tasks. It consisted of:
Encoder block: That accepts an input to be translated
Decoder block: That returns the translated input as an output
This architecture was modified for text generation tasks. This involved removing the Encoder and adopting a Decoder-only architecture. This Decoder-only transformer is the one that is used by modern LLMs.
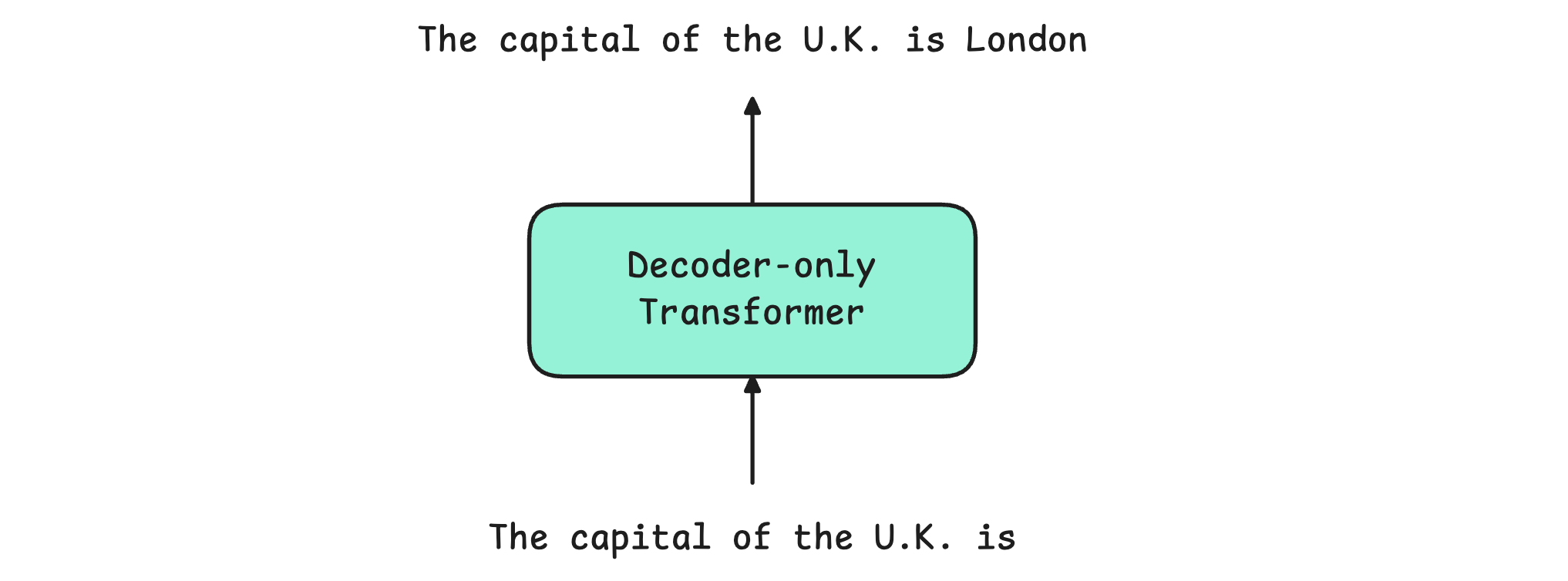
Let’s learn what components make the Decoder-only Transformer so impressive.
The components of the Decoder-only Transformer
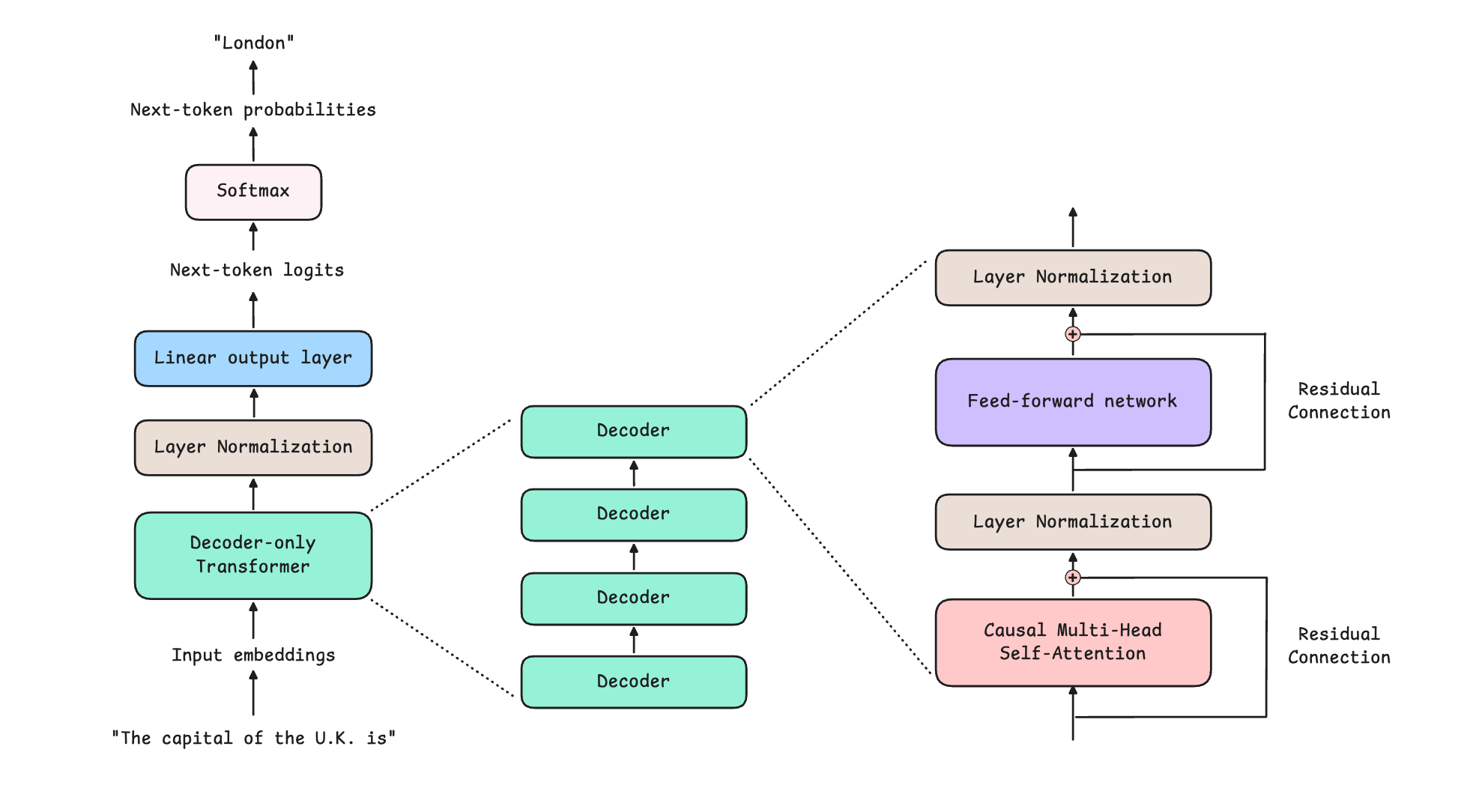
A Decoder-only Transformer is composed of multiple identical Decoders stacked on top of each other (the output of one is passed as input to the next).
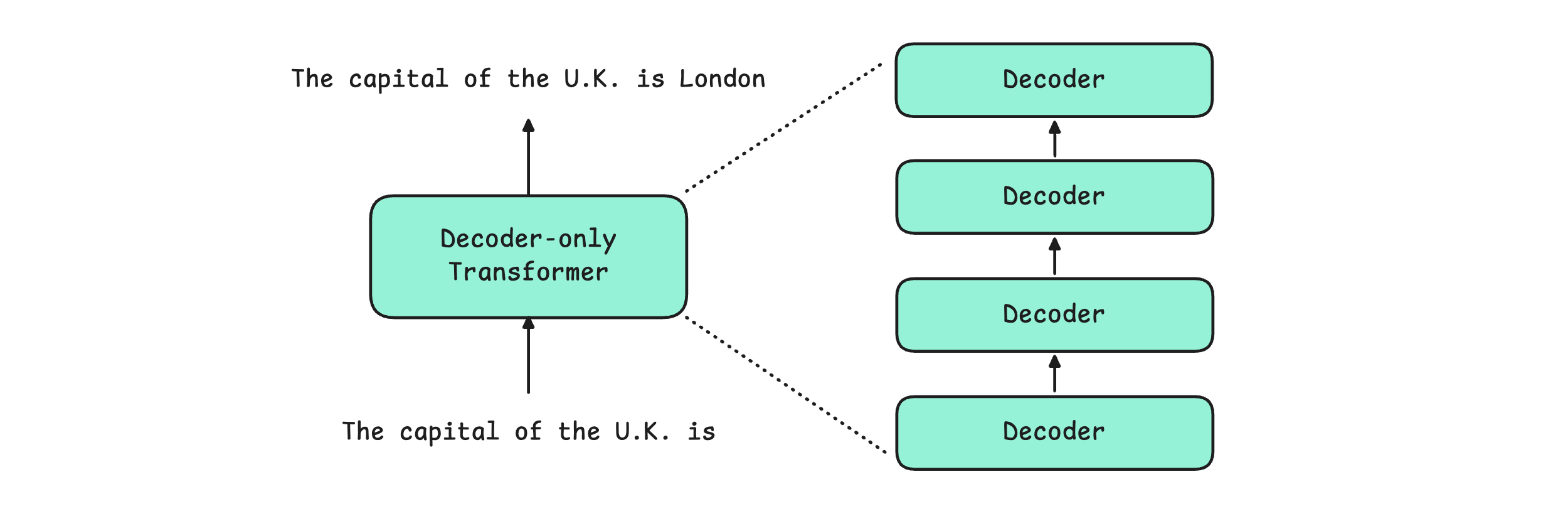
Each Decoder consists of 4 components:
Causal (or Masked) Multi-Head Self-Attention
Feed-Forward Network
Layer Normalization
Residual or Skip connections
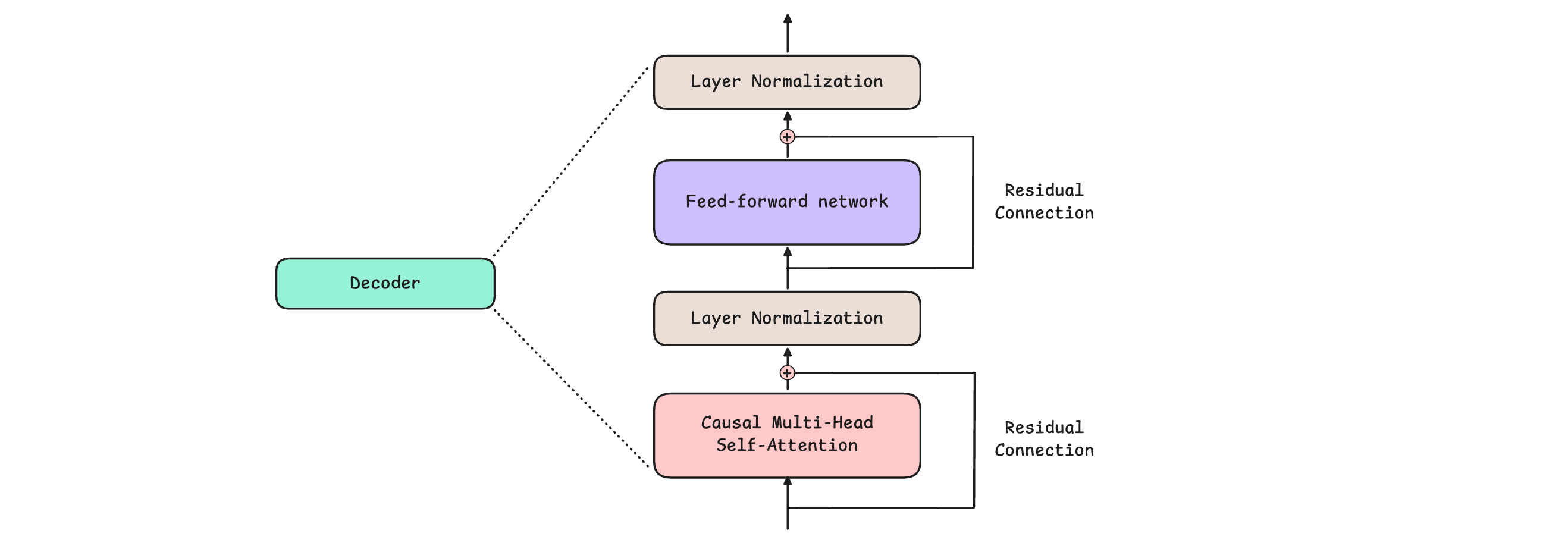
The above architecture is from GPT-1, published in 2018. Since then, it has been seen that applying Layer Normalization before Causal Multi-Head Self-Attention and Feed-Forward Network, an architecture pattern called Pre-LayerNorm, leads to better training performance. Hence, modern LLMs use the Pre-LayerNorm architecture.
Let’s learn the role of each of these components in detail next.
1. Causal (or Masked) Multi-Head Self-Attention
Attention helps a model learn dependencies between different tokens so that it can understand context, syntax, and semantics in text well.
The term “Causal (or Masked) Multi-Head Self-Attention” is understood better when we break it down into parts as follows:
Attention: This general architecture allows tokens across different text sequences to focus on one another.
Self-Attention: This is when Attention is applied in a way that lets tokens in the same text sequence focus on each other.
Multi-Head Self-Attention: This architecture extends Self-Attention by using multiple parallel Self-Attention blocks (heads), rather than a single one. This helps it to better learn different types of semantic relationships within the input text sequence.
Causal (or Masked) Multi-Head Self-Attention
Decoder-only Transformer based LLMs generate text tokens one at a time, keeping past tokens as context at each step of generation.
During training, for a given input sequence, they must learn to generate each token based on previous tokens, without peeking at future tokens.
Consider this training text sequence:“The sky is blue”
During training to generate the token “is“, the model can learn to generate it from both the past tokens (”The“ and “sky“) and future ones (”blue“).
During generation, since the model has no access to future tokens (it hasn’t generated them yet), it can’t use the strategy of generating text from them, leading it to perform poorly. Hence, we need an Attention mechanism that can mask future tokens during training.This is made possible using the Causal or Masked Multi-Head Self-Attention, which ensures that each token in the training sequence can attend only to previous tokens and itself, not to future tokens.
Each of these attention mechanisms is Scaled dot-product attention, mathematically, as shown below.

The internals of the Causal multi-head self-attention mechanism are shown below.
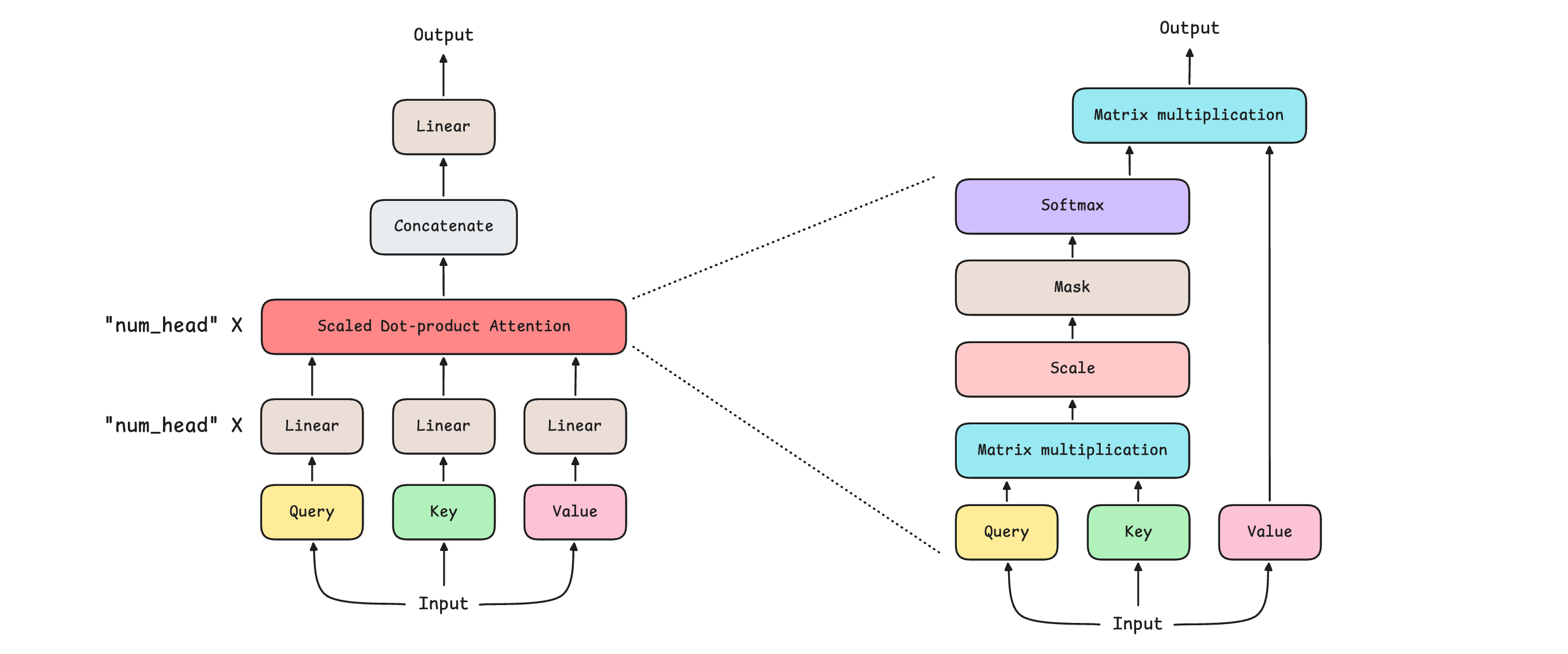
Modern LLMs use many other variants of the attention mechanism, such as:
Compressed Sparse Attention (CSA) and Heavily Compressed Attention (HCA) as in DeepSeek-V4
2. Feed-Forward Network
While the role of the Causal Multi-Head Self-Attention is to understand inter-token patterns (between different tokens) in text, the Feed-forward network (FFN) helps learn token-wise patterns or deeper individual representations of tokens.
The following Feed-forward network expands the input dimension using fully connected layers to increase representational capacity, then projects it back to the original dimension before passing it to the next layer.
A feed-forward network can use multiple wide, fully connected layers, along with different activation functions such as SwiGLU. A simple feed-forward network is shown below.
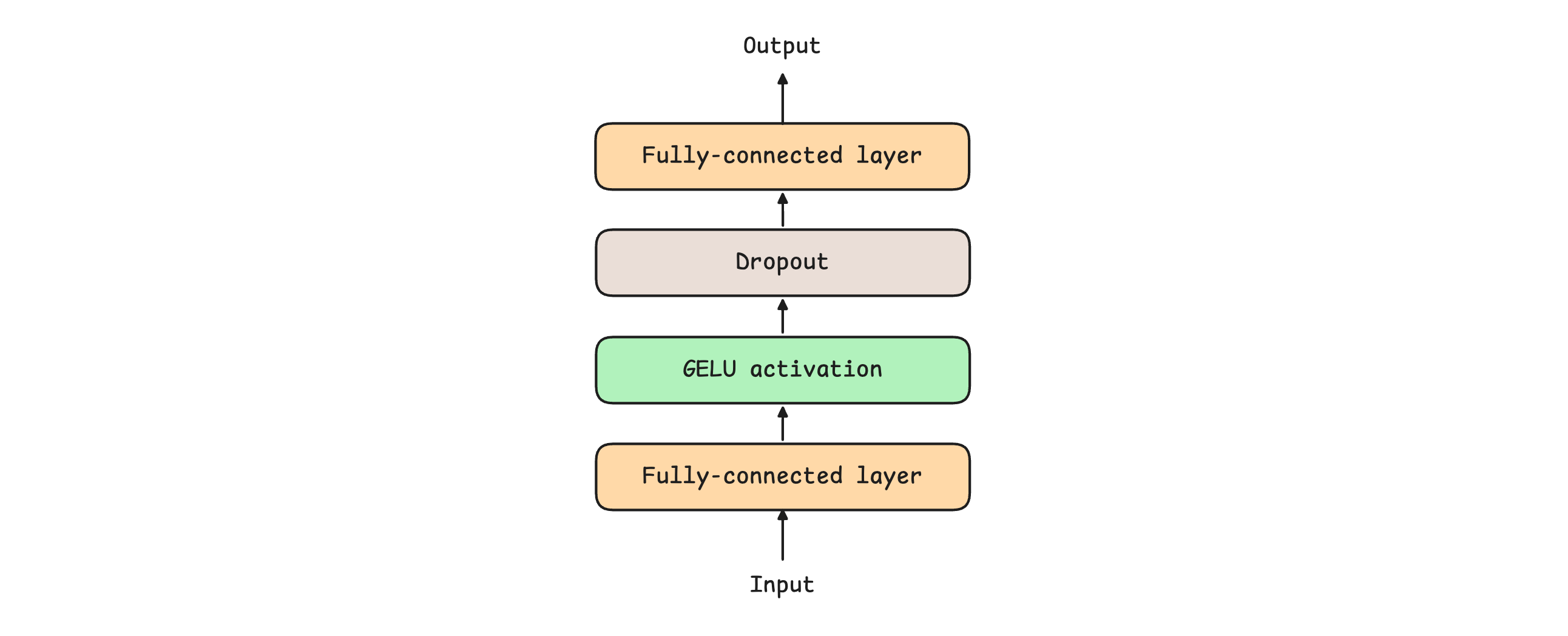
3. Layer Normalization
Layer Normalization, or LayerNorm, helps stabilize and speed up model training by keeping each token’s representation well-scaled and gradients numerically stable as they flow through the layers of a Transformer.
It does so by normalizing each token’s feature vector to zero mean and unit variance, then applies learned scaling and shifting.
There are two ways in which LayerNorm is used:
Post-LayerNorm (Post-LN): where LayerNorm is applied after each sublayer as in the original Transformer paper.
Pre-LayerNorm (Pre-LN): where LayerNorm is applied before each sublayer, as in architectures like GPT-2, leading to more stable gradients during training.

Many modern LLMs, such as Qwen 3, use RMSNorm with pre-normalization instead of Pre-LayerNorm because it is computationally cheaper and offers faster training and inference while maintaining comparable model performance.
4. Residual/ Skip connection
A Residual or Skip connection adds the input of a layer directly to its output, bypassing the layer.
Such connections help information and gradients flow through deep networks, making training more stable and effective.
Residual connections were first implemented in Image recognition models, and given their effectiveness, they are now used in all LLMs today, either in their original form or a modified form such as:
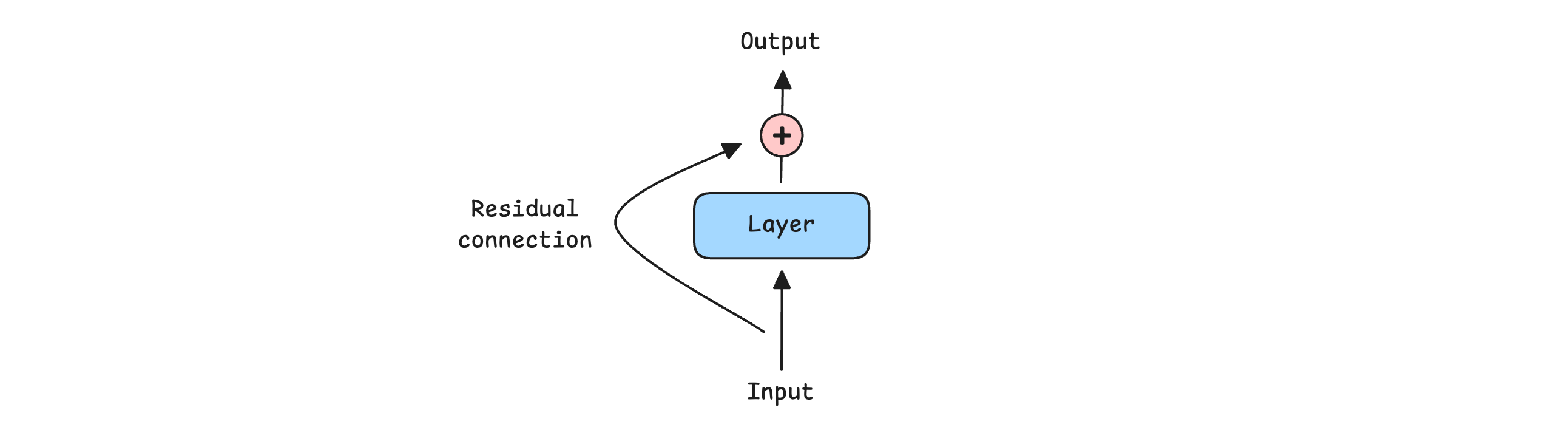
All of the above-described components come together to form the Decoder-only Transformer, an architecture that lies at the heart of modern LLMs.
The flow through an LLM goes like this:
An input sequence is tokenized (broken down into tokens) and converted into input embeddings (which contain a high-dimensional representation of input tokens and their positions in the sequence)
These are processed by a stack of Decoder blocks in a Decoder-only transformer
A Layer Normalization is applied to the output of the transformer stack
A Linear output layer takes the last token’s vector and turns it into a list of logits
These logits are converted into token probabilities
Different decoding strategies are used to pick a token from these probabilities. This is the next token produced by the LLM, given the input sequence.
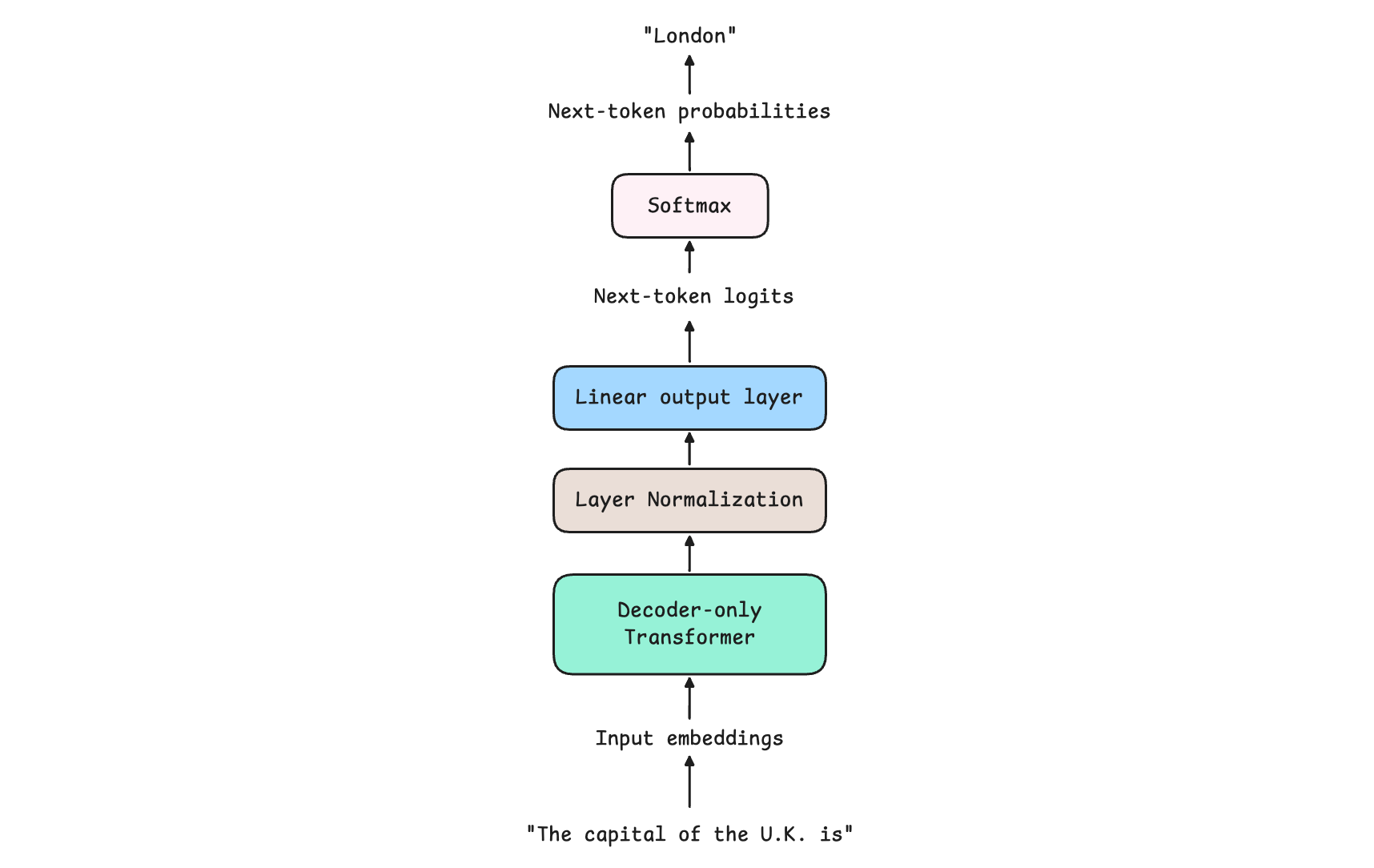
A more detailed illustration of each component is shown below.
If you’re curious about learning more about these components and how a complete LLM works and is trained, with code, this series of articles will help.
Thank you for reading!
If you found it valuable, hit a like ❤️ and consider subscribing for more such content every week.
If you have any questions/suggestions, feel free to leave a comment.
 | A guest post by
|
it never gets old!
Thanks for sharing!!