

The secret architecture behind "username already taken"

When you try to sign up on a platform like Instagram and type in your username, the system almost instantly tells you whether it’s available or not. If it’s taken, it even suggests alternatives on the spot.
For a small startup with only a few thousand users, this check is simple—a quick database query will do. But for platforms like Instagram, Google, or X (formerly Twitter), with billions of users, the challenge is far greater.
They can’t possibly scan through billions of records every time someone signs up.
So how do they make it happen in the blink of an eye?
In this article, we will walk through the journey of how these systems are built, starting with the most basic approach and leveling up to the sophisticated architecture used at Big Tech scale.
Level 1: Querying the Database Directly
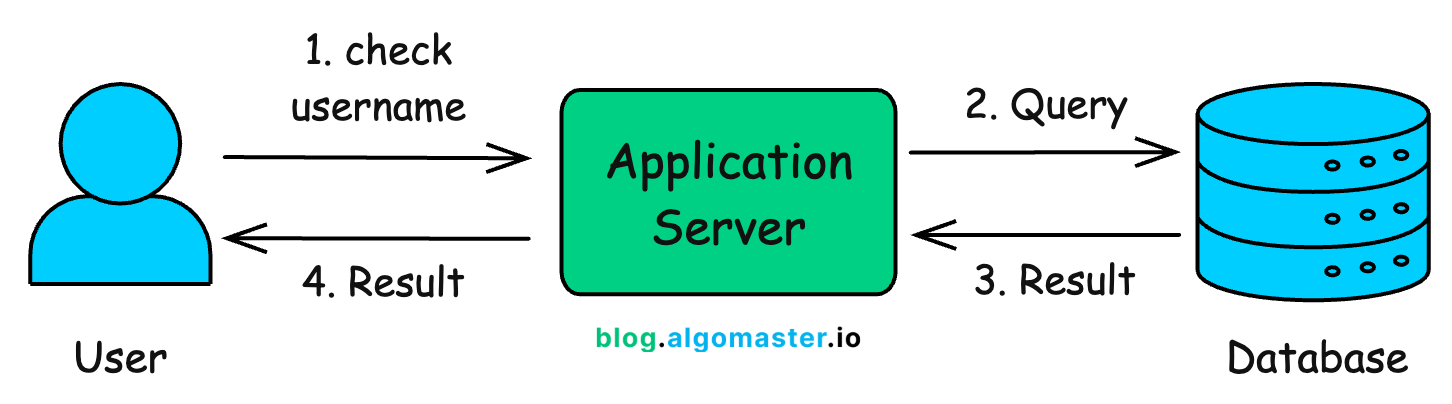
The most straightforward way to check if a username exists is to query the database:
SELECT COUNT(1)
FROM users
WHERE username = ‘new_user’;If the count is greater than zero, the username is already taken. If it’s zero, the username is available.
Simple, right?
For a small system with thousands or even a few million users, this works just fine. A well-indexed relational database can return the result in milliseconds.
But things start to look very different once you scale to hundreds of millions or even billions of users, spread across multiple servers and data centers.
Indexes grow massive: Even with efficient data structures like B-trees or hash indexes, scanning and maintaining them takes longer.
Databases get overloaded. Every sign-up attempt means another query, creating heavy read traffic on already busy systems.
In short: while direct queries are precise and easy to implement, they simply don’t scale to the demands of Big Tech. At billions of records, this approach would quickly grind to a halt.
Level 2: Adding a Cache
The next natural optimization is caching.
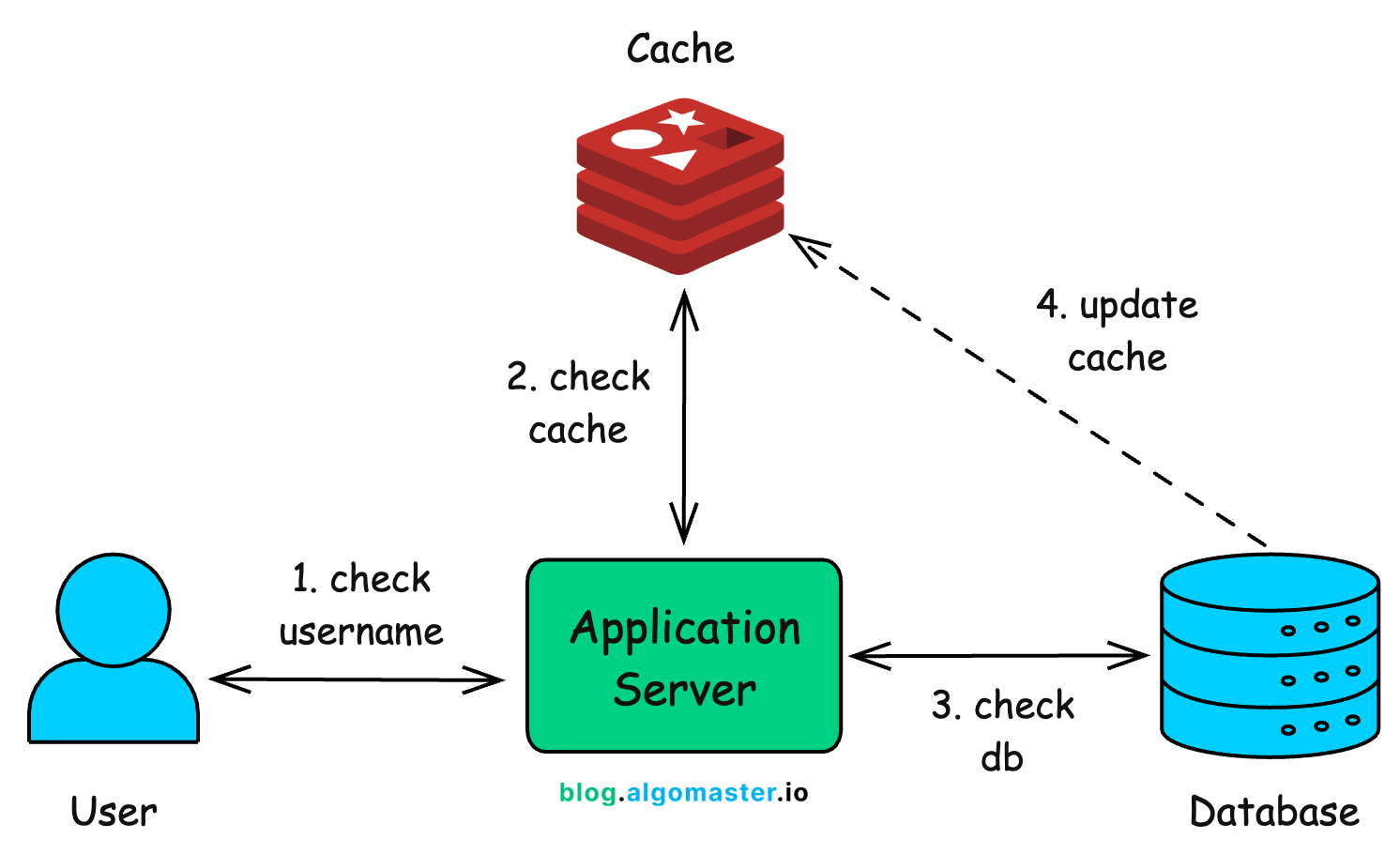
Instead of hitting the database every single time a user tries a new username, we keep a temporary copy of frequently checked usernames in memory (using tools like Redis or Memcached).
Here’s the typical flow:
User enters a username: The request first goes to the application server.
Cache check (primary): The system checks the cache to see if this username has been queried recently.
If found → return the result instantly (no need to touch the database).
If not found → move on to the database.
Database check (fallback): If the cache misses, the application queries the database for the authoritative result.
Update cache (future optimization): Once the database returns the answer, the system updates the cache so the next time someone checks the same username, it’s available instantly from memory.
This works beautifully for usernames that are checked often. For example, if thousands of people keep trying names like john, alex, or princess, the cache can serve those requests instantly without touching the database at all.
But caching introduces new trade-offs:
Limited memory. You can’t possibly store billions of usernames in memory forever, it’s just too expensive. Systems often rely on eviction policies like Least Recently Used (LRU) to keep only the “hot” entries.
Stale data. If a username becomes available (say a user deletes their account), but the cache isn’t updated in time, the system may mistakenly think it’s still taken. This is usually solved with time-to-live (TTL) values so cached data eventually expires.
Cache misses. Unique usernames still have to go all the way to the database the first time they’re queried.
Level 3: Using Bloom Filters
Now things get interesting.
Instead of storing every single username explicitly in memory or querying the database each time, what if we stored a compact “fingerprint” that could tell us whether a username might exist?
This is exactly what Bloom Filters are designed for.

What is a Bloom Filter?
A Bloom filter is a probabilistic data structure that can very quickly answer the question: “Might this username exist in the system?”
If the filter says NO, you can be 100% sure the username does not exist.
If it says YES, the username might exist, and you double-check in the cache or database.
Bloom filters trade a tiny probability of false positives for extreme speed and memory efficiency.
Why Bloom Filters are Powerful
Space-efficient: With ~1.2 GB of memory, a Bloom filter can represent around 1 billion usernames with just a 1% false positive rate.
Fast: Checking a few bits in memory is much faster than hitting a cache or database.
How Bloom Filters Work
Here’s how it works:
Initialization: A Bloom filter starts as a large array of bits, all set to
0.Adding a Username
Suppose a user signs up with
“new_user”.The username is run through several different hash functions (say 3–10).
Each hash function produces a position in the bit array, and those positions are flipped to
1.
Checking a Username
When someone later tries
“new_user”, the same hash functions are applied.The system checks the corresponding bits:
If any bit is 0, the username has definitely never been seen → it’s available.
If all bits are 1, the username is probably taken.
The Catch: False Positives
Sometimes, a new username’s hash positions may overlap with ones set by other usernames. This means the filter might say “maybe taken” when the username is actually free.
That’s why Bloom filters are always followed by a cache or database check for confirmation in case of false positives (~1% of the requests).
Putting it all together
When you type “my_cool_username” and hit enter, here’s what happens behind the scenes in a large-scale system:
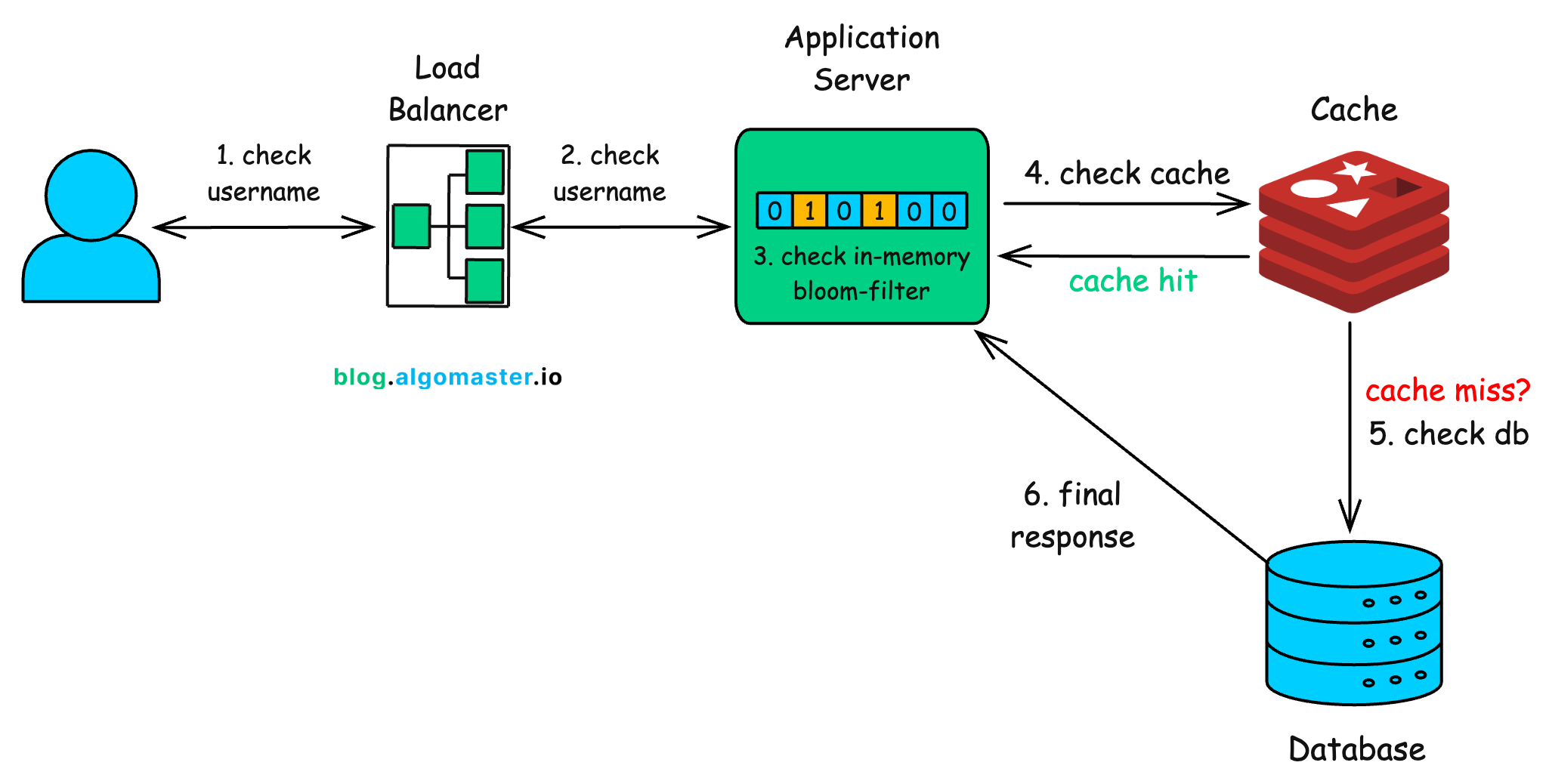
Load Balancer: Your request first first hits a load balancer, which routes it to the nearest or least-busy server.
Bloom Filter (Primary Check)
The server first checks in-memory Bloom filter.
If the Bloom filter says “Definitely Not Taken”, the server instantly returns the response “Available!“
Most usernames are unique, so the vast majority of requests end here, without touching the cache or database.
Cache Check (Secondary Check)
If the Bloom filter says “Probably Taken”, the system consults the distributed cache (Redis/Memcached).
If the username was checked recently, the cache instantly returns the definitive answer.
Database Check (Final Check)
Only if the cache also misses does the request go to the main database.
This is not a single machine but a distributed system (Cassandra, DynamoDB, or Spanner) spread across thousands of servers.
Under the hood, indexing structures like B+ Trees keep lookups efficient—
O(log n)even at massive scale.
Respond & Update
The database returns the final yes/no.
On the way back, the result is written into the cache so the next lookup for the same username is instant.
This layered approach acts as a funnel, where each step filters out a large number of requests, ensuring that only a tiny fraction ever need to make the “expensive” trip to the main database.
Level 4: Beyond Basic Lookups
Up to this point, we’ve been talking about simple yes/no checks: Does this username exist or not?
But real-world platforms like Instagram go further. They also suggest alternative usernames if your first choice is taken.
Take the username daniel for example. If it’s already in use, Instagram might suggest:
daniel_123daniel_devdaniel2025
These features require something smarter than a cache or a Bloom filter. They rely on a data structure purpose-built for prefix-based lookups: the Trie (Prefix Tree).
What Is a Trie?
A trie is a tree-like structure that organizes strings by their shared prefixes. Instead of storing usernames as whole words, it breaks them down character by character, reusing common paths.
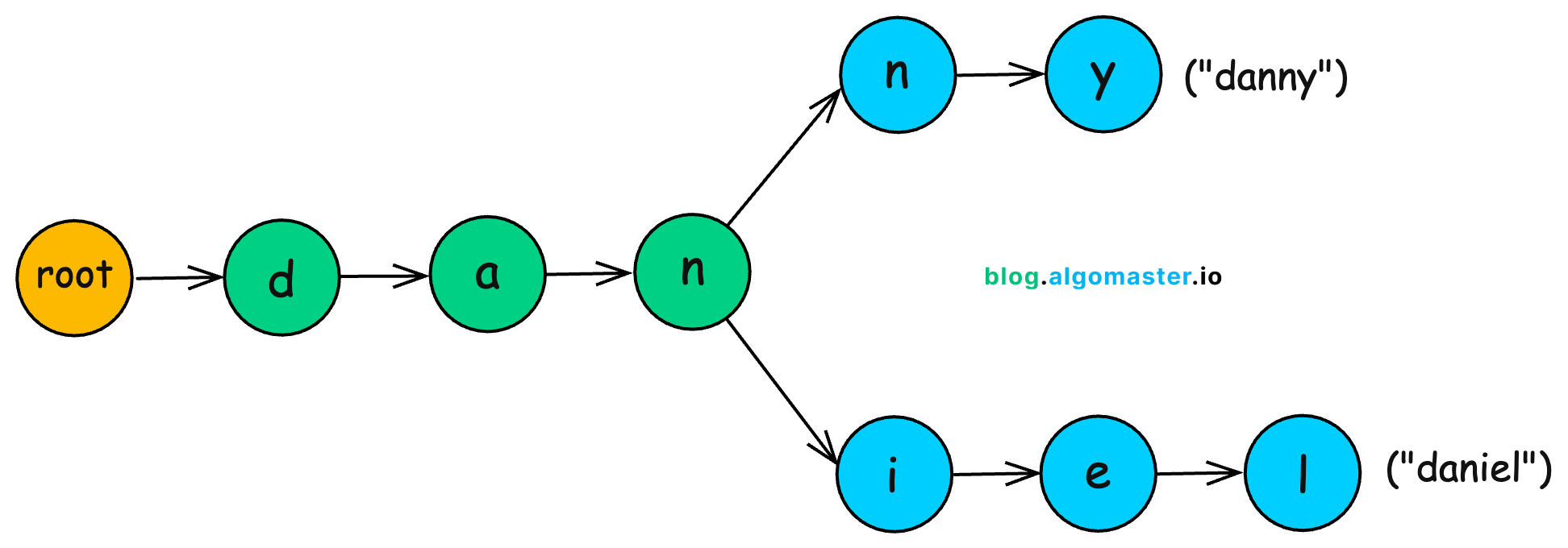
For example:
danielbecomesd → a → n → i → e → ldannyshares the pathd → a → nbefore branching inton → y.
Tries unlock a set of capabilities that databases and caches struggle with:
Fast lookups: Checking whether a username exists takes time proportional only to the length of the string (
O(M)), not the total number of usernames.For
“daniel”, that’s just 6 steps even if there are billions of usernames in the system.
Autocomplete: By following a partial path, the trie can instantly list all usernames starting with a given prefix (e.g.,
“dan”).Suggestions: Since similar usernames share common paths, generating alternatives like
daniel_devordaniel2025becomes easy and efficient.
Tries come with trade-offs too:
Memory Hungry: If usernames don’t share many prefixes, the trie branches can grow explosively, consuming large amounts of memory.
Update Overhead: Inserting or deleting usernames in real-time requires careful synchronization in distributed environments.
To reduce memory usage, compressed tries (also called radix trees) are often used.
Instead of storing every single character as a node, compressed tries collapse chains of single-child nodes into one edge.
This saves both space and lookup steps, making the structure more practical at scale.
Thank you for reading!
If you found it valuable, hit a like ❤️ and consider subscribing for more such content.
If you have any questions or suggestions, leave a comment.
P.S. If you’re enjoying this newsletter and want to get even more value, consider becoming a paid subscriber.
As a paid subscriber, you’ll unlock all premium articles and gain full access to all premium courses on algomaster.io.
There are group discounts, gift options, and referral bonuses available.
Checkout my Youtube channel for more in-depth content.
Follow me on LinkedIn, X and Medium to stay updated.
Checkout my GitHub repositories for free interview preparation resources.
I hope you have a lovely day!
See you soon,
Ashish
Great post, seeing some things come up again and again.
Awesome post!!