

Why You Should NEVER Start With Microservices
The hidden costs of premature optimization

You’re starting a new project. You’ve read about how Netflix, Amazon, and Uber use microservices to handle millions of requests.
You want to build something scalable from day one.
So you begin designing your system with separate services for users, orders, payments, notifications, and inventory. Each with its own database, its own deployment pipeline, its own monitoring setup.
Six months later, you have 15 services, a team of 3 developers, and you’re spending 80% of your time debugging distributed system issues instead of building features.
This is the microservices trap, and it catches more teams than you might think.
In this article, I’ll explain:
Why microservices are exciting but dangerous for new projects
The hidden costs that nobody talks about
When microservices actually make sense
The “Monolith First” approach and why it works
Why microservices are important in System Design Interviews
The Microservices Hype
Microservices sound exciting and they always look impressive in system design interviews.
The idea of having small, independent services that can be developed, deployed, and scaled independently sounds like engineering nirvana.
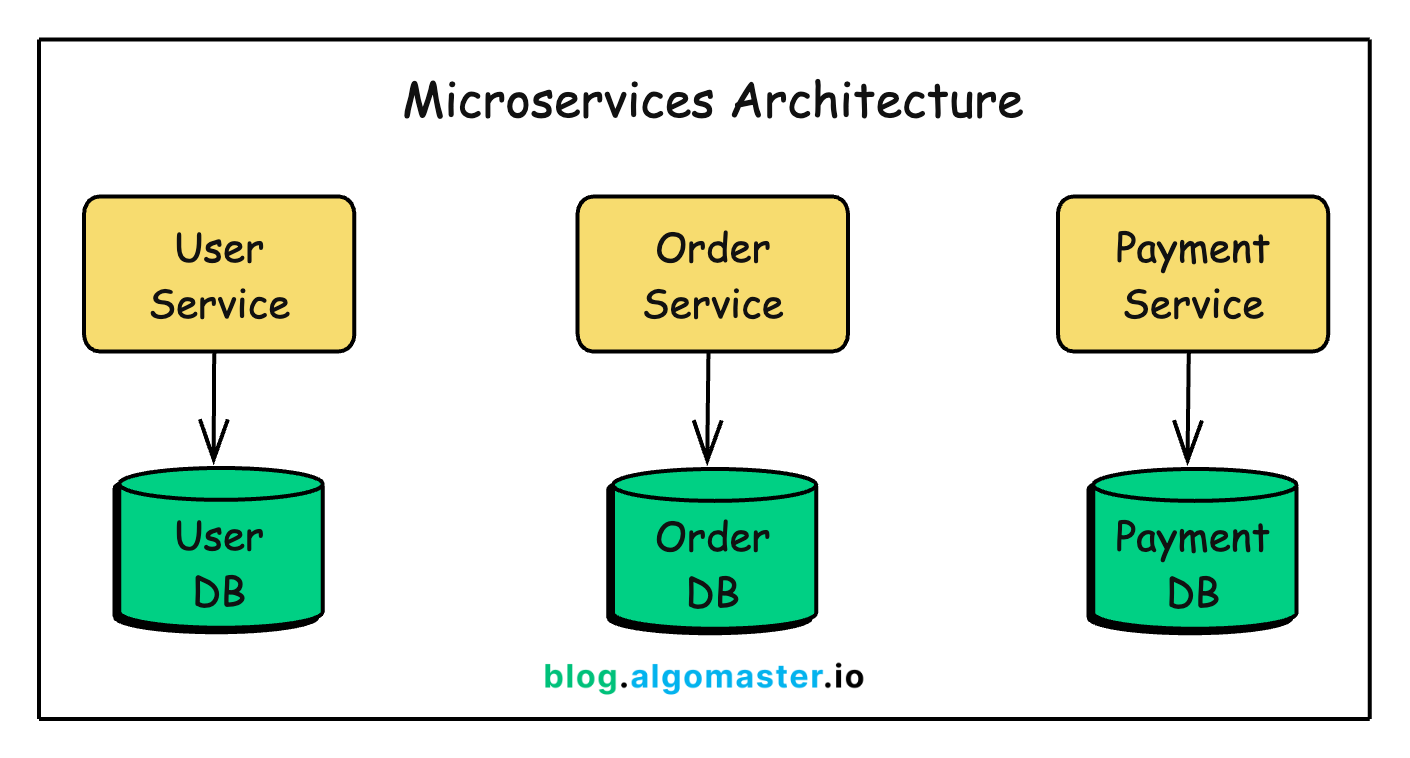
When you read about microservices, you hear about:
Independent deployments: Deploy one service without affecting others
Technology flexibility: Use the best language/framework for each service
Team autonomy: Small teams own their services end-to-end
Scalability: Scale only the services that need it
Fault isolation: One service failure doesn’t bring down the system
These benefits are real. But they come with a catch.
These benefits only materialize at scale, both in terms of traffic AND team size.
For a startup or small team, microservices don’t just fail to provide these benefits. They actively work against you.
Let me show you why.
The Hidden Costs of Microservices
1. Distributed Systems Complexity
The moment you split your application into multiple services, you’ve created a distributed system. And distributed systems are hard.
Problems that didn’t exist in a monolith suddenly become your daily reality:
Network failures - Service A can’t reach Service B. Now what?
Latency - A function call that took microseconds is now a network call taking milliseconds
Data consistency - How do you maintain consistency across multiple databases?
Debugging nightmares - A single request might touch 10 services. Good luck tracing that error.
In a monolith, calling a function is guaranteed to either work or throw an exception.
In microservices, a service call can:
Succeed
Fail with an error
Timeout (but did it actually succeed?)
Succeed but return stale data
Succeed on retry but cause duplicate operations
Each of these scenarios requires different handling. Multiply this by every service-to-service call in your system.
What about debugging?
In a monolith you get a stack trace.
In a microservices architecture, a single user request might touch 10 different services. When something goes wrong, you need to trace through logs across all of them, correlate timestamps, and figure out which service caused the failure.
But distributed complexity is just the beginning. How do you even manage all these services?
2. Operational Overhead
A monolith means one thing to deploy, monitor, and maintain.
With microservices, everything multiplies:
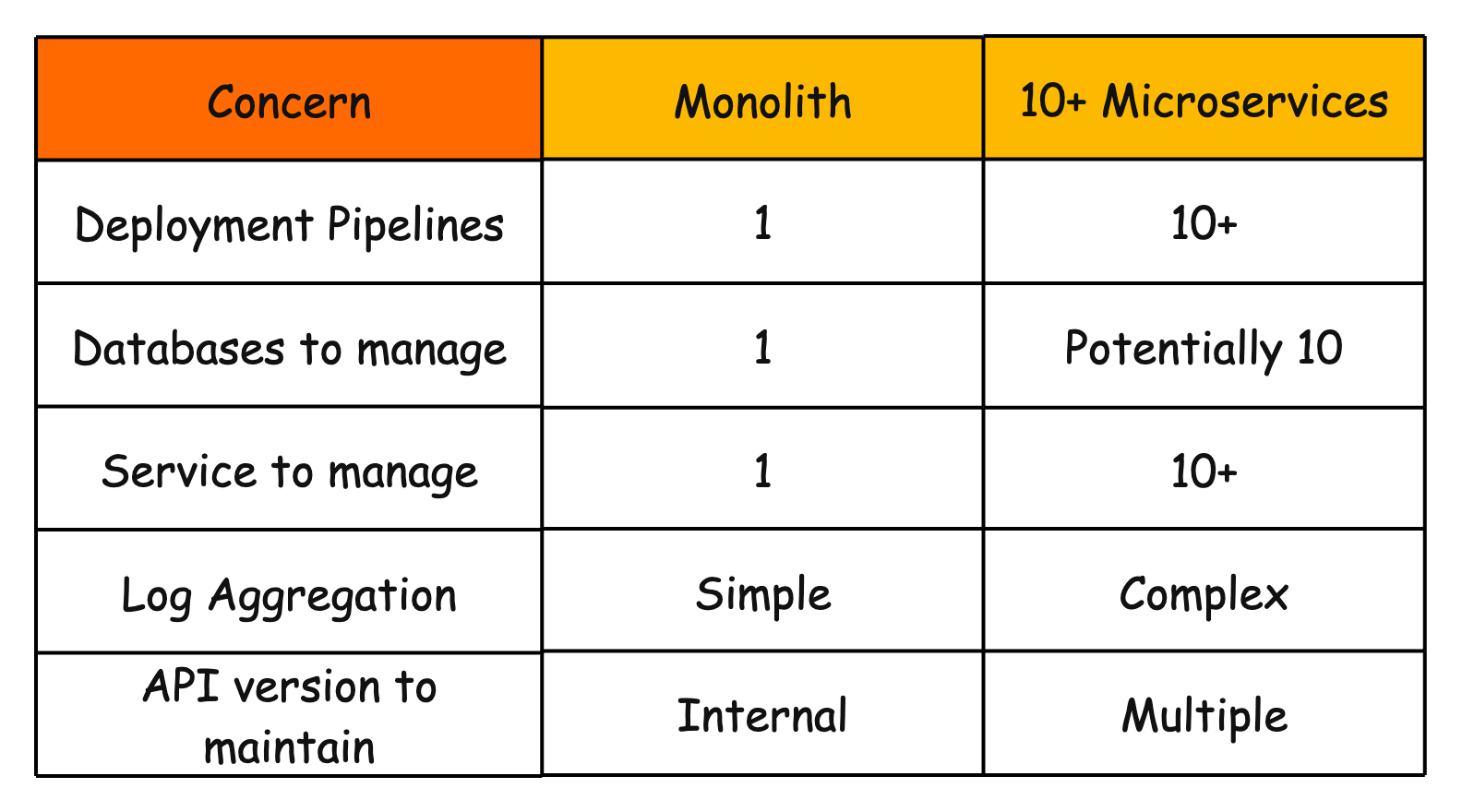
You’ll also need additional infrastructure that a monolith simply doesn’t require:
Service discovery: How do services find each other?
API Gateway: How do external clients reach your services?
Distributed tracing: How do you debug across services?
Circuit breakers: How do you handle cascading failures?
Message queues: How do services communicate asynchronously?
Each of these adds complexity, cost, and potential failure points. A small team can easily spend more time managing infrastructure than building features.
Speaking of performance costs, let’s look at what happens to your application’s speed.
3. Network Is Now Your Bottleneck
In a monolith, data access is fast (~1 microsecond). Objects are in memory or a single database call away.
In microservices, what was once a method call is now:
1. Serialize request to JSON ~0.5ms
2. DNS lookup ~1-10ms
3. TCP connection ~1-5ms
4. TLS handshake ~5-30ms
5. Send HTTP request ~1-5ms
6. Service B processes ~varies
7. Serialize response ~0.5ms
8. Network transfer back ~1-5ms
9. Deserialize response ~0.5ms
Time: 10-50+ milliseconds (10,000x slower!) This overhead adds up quickly. A page that required 5 internal method calls in a monolith might now require 5 network calls, each adding 10-50ms of latency.
4. Data Management Becomes a Nightmare
One of the “benefits” of microservices is that each service owns its data. But this creates serious challenges.
The Join Problem
In a monolith, you can easily join users with orders with products in a single SQL query:
SELECT u.name, o.total, p.title
FROM users u
JOIN orders o ON u.id = o.user_id
JOIN order_items oi ON o.id = oi.order_id
JOIN products p ON oi.product_id = p.id
WHERE u.id = 123;In microservices, the same data lives in different databases:
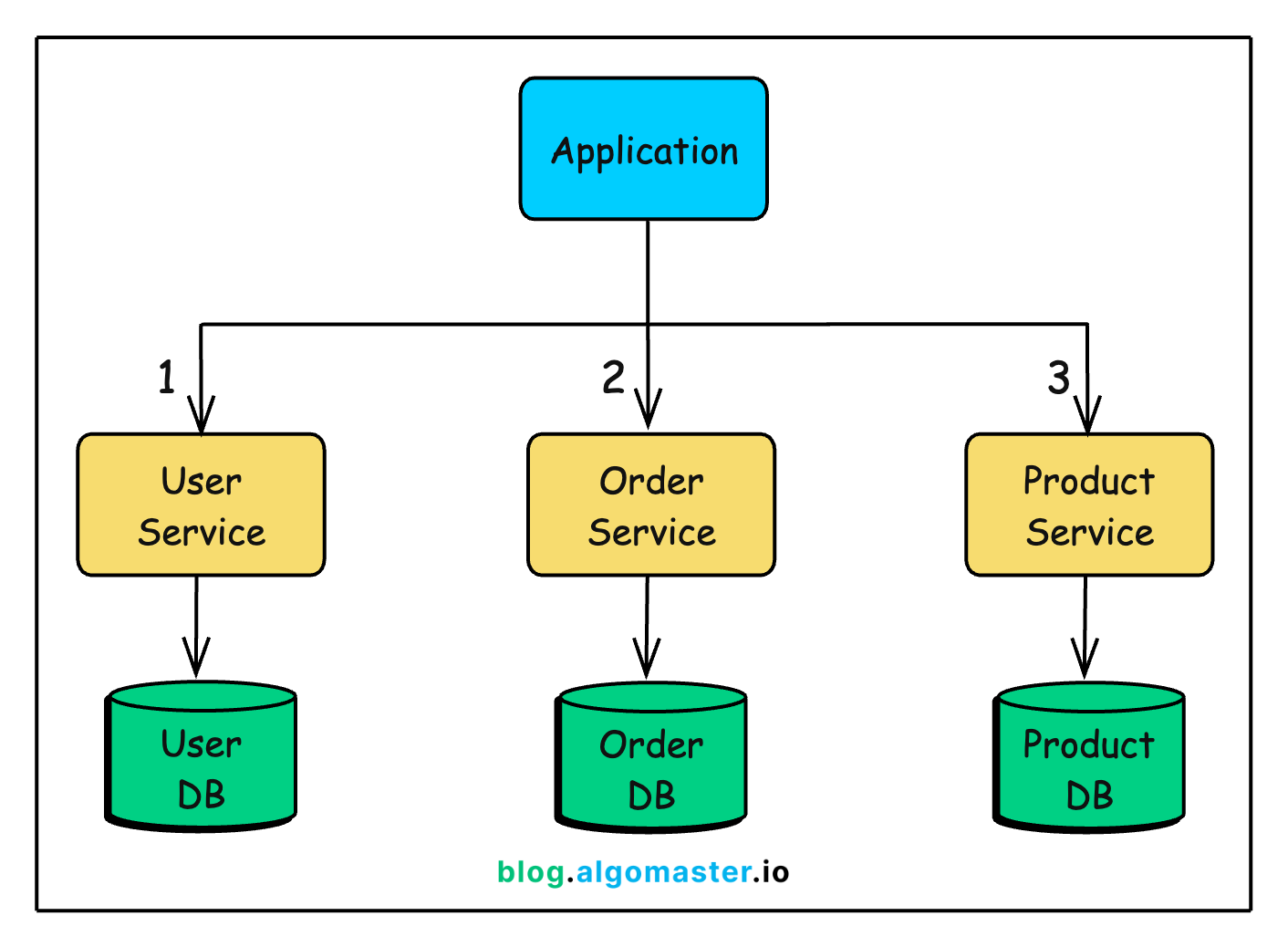
To get user + orders + products, you need to:
Call the Users service
Call the Orders service
Call the Products service
Join the data in your application code
The Transaction Problem
In a monolith, you can wrap multiple operations in a database transaction:

In microservices, each service has its own database. You can’t have a transaction span multiple services. Instead, you need distributed transactions or saga pattern - both are complex and error-prone.
5. Testing Is Exponentially Harder
Testing a monolith is straightforward: spin up the application, run your tests.
Testing microservices requires multiple layers:
Contract testing between services
Integration tests that spin up multiple services
End-to-end tests across the entire system
Chaos engineering to verify fault tolerance
Your CI/CD pipeline becomes a complex orchestration of building, deploying, and testing multiple services in the correct order. A change to a shared API requires updating and testing all dependent services.
6. You Don’t Know Your Domain Yet
This might be the most important point.
When you’re starting a new project, you don’t fully understand your domain.
Requirements will change. You’ll discover that what you thought were separate concerns are actually deeply intertwined.
In a monolith, refactoring is moving code between packages. In microservices, refactoring is redesigning APIs, migrating data, and coordinating deployments across teams.
Martin Fowler calls this the Monolith First approach:
“Almost all the successful microservice stories have started with a monolith that got too big and was broken up.”
— Martin Fowler
Starting with microservices means you’re drawing service boundaries before you understand where they should be. And wrong boundaries are incredibly expensive to fix.
So when do microservices actually make sense?